从 Linux 命令行将 PDF 转换为图像

将 PDF 文件转换为图像可以在 Linux 命令行中使用单个命令轻松完成。了解如何安装该实用程序、如何使用它以及如何自动执行设置。
什么是 poppler-utils ?
正如本文介绍中提到的,我们需要安装一个名为 poppler-utils 的小型实用程序集来帮助我们将 PDF 文件转换为图像。
poppler-utils 实用程序集允许我们将图像转换为 PDF,以及将 PDF 转换为图像。
安装 poppler-utils
要在基于 Debian/Apt 的 Linux 发行版(如 Ubuntu 和 Mint)上安装 poppler-utils,请执行以下操作:
sudo apt install poppler-utils
要在基于 RedHat/Yum 的 Linux 发行版(如 RedHat 和 Fedora)上安装 poppler-utils,请执行以下操作:
sudo yum install poppler-utils
将 PDF 转换为图像
所需的命令简单明了:
pdftoppm -png test.pdf test
使用 pdftopm 命令,我们可以将 PDF 转换为图像。我们指定我们想要一个 PNG 文件作为输出格式(通过使用 -png)并且我们的输入文件是 test.pdf。
我们指定为 test 的输出文件。 pdftopm 将自动添加页码后缀(如 -1)和扩展名(基于之前传递的 -png 选项)。
因此,输出文件名将是 test-1.png,我们接下来可以验证:
ls test-1.png
eog test-1.png
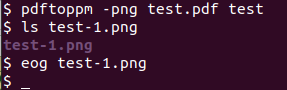
任何后续页面将是 test-2.png 等。eog 命令(如果安装了 eog)将为您打开该文件,以便您可以查看输出,但您可以使用您喜欢的任何其他图像处理程序。
将 PDF 文件批量处理为图像
我们可以制作一个单行命令来批量处理所有具有给定名称的 PDF 文件到图像。然后我们可以简单地将此行添加到一个小脚本 .sh 文件中并进一步自动化,或者我们可以在需要将大量 PDF 文件转换为图像时在命令行中使用它。
ls --color=never test*.pdf | sed 's|.pdf||' | xargs -I{} pdftoppm {}.pdf -png {}在此命令中,我们首先获取所有 PDF 文件的目录列表,这些文件的名称以 test 开头并以 .pdf 结尾,使用 ls -- color=从不测试*.pdf。
--color=never 很重要,因为 shell 颜色编码符号(如果激活,默认情况下)有时可能会混淆 xargs。
接下来,我们使用一个简单的 sed 替换命令将一个字面量点和 pdf 替换为空。换句话说,我们删除了 .pdf 文件扩展名。
这给了我们稍后仅在需要时将其添加回来的好处,即当为 pdftopm 指定输入文件时,而不是在为相同的 pdftopm 命令指定输出文件时,与我们上面的早期示例非常相似。
最后,我们使用 xargs 将每个 pdf 文件名(减去 .pdf)一个一个地发送到 pdftopm。我们将 -I 选项用于 xargs,它允许我们通过简单地使用 {} 来指定收到的任何输入(即缩短的 pdf 文件名)接下来的命令。
如您所见,我们的 pdftopm 命令现在看起来与第一个示例非常相似,每个单独的 pdf 文件名作为输入(重新以 .pdf 为后缀),并且作为输出不包含 .pdf 的 pdf 文件名。
让我们执行它:

这工作得很好:三个 PDF 文件,每一个都有一页,被转换为三个单独的 .png 文件(每页一个图像,在这种情况下每个 PDF 因为每个 PDF 只有一页),所有名称和后缀都正确。
作为 -png 选项的替代方案,还可以使用 -jpeg 来生成 JPEG 文件。使用 pdftopm --help 或 man pdftopm 查看完整的选项列表。
包起来
在本文中,我们看到了将 PDF 文件转换为图像文件是多么简单和直接,而且是直接从 Linux 命令行完成的!我们还研究了一种使此过程自动化的直接方法。 尽情享受吧!