如何在 Ubuntu 20.04 上安装 ELK 堆栈
当许多不同的服务和应用程序部署在多个服务器上时,提取所有日志并从中获取有意义的操作见解并不是一件容易的任务。这就是 ELK 堆栈发挥作用的地方。正确部署和配置后,ELK 平台允许您以快速、可扩展且可靠的方式整合、处理、监控和分析多个来源生成的数据。
在本教程中,您将学习如何在 Ubuntu 20.04 平台上配置 ELK 堆栈。在深入探讨主题之前,我们先来了解一下ELK堆栈是什么,它能解决什么问题。
什么是 ELK 堆栈以及为什么使用它?
作为一个强大的生产级日志分析平台,ELK 堆栈包含三个免费的开源软件:Elasticsearch、Logstash 和 Kibana,这也是缩写词。这些软件组件中的每一个都在日志分析中发挥着独特的作用。
Elasticsearch:一种搜索引擎,可以使用分布式分片存储来存储和搜索基于文本的数据。这是整个堆栈的核心。
Logstash:一个数据处理组件,用于收集、解析和转换数据,然后将数据发送到 Elasticsearch 进行存储。
Kibana:基于 Web 的数据可视化仪表板,提供界面,您可以通过该界面对收集的数据进行探索和运行分析。
另一个经常与 ELK 堆栈一起讨论的开源工具是 Beats。 Beats 是轻量级传输代理,其唯一目的是从服务器收集应用程序数据并将其发送到 Elasticsearch 或 Logstash。根据传输的数据类型,可以使用不同类型的 Beats。在这篇文章中,我们将使用 Filebeat,它的创建主要是为了读取日志文件。
借助 ELK,您将能够从一个集中位置收集、搜索、分析和可视化应用程序日志数据。该堆栈可以通过灵活的数据处理管道来处理不同类型的数据。它通过将数据分布在存储节点集群中,可以高效、可扩展地处理大量数据。处理和存储后,数据可供领域专家在完全可定制的仪表板中检查和分析。
您可以将 ELK 堆栈的每个元素分别部署在多一台服务器上,并且可以根据需要通过添加更多服务器来扩展每个元素。在典型的生产环境中,ELK堆栈的部署通常由Kubernetes协调。
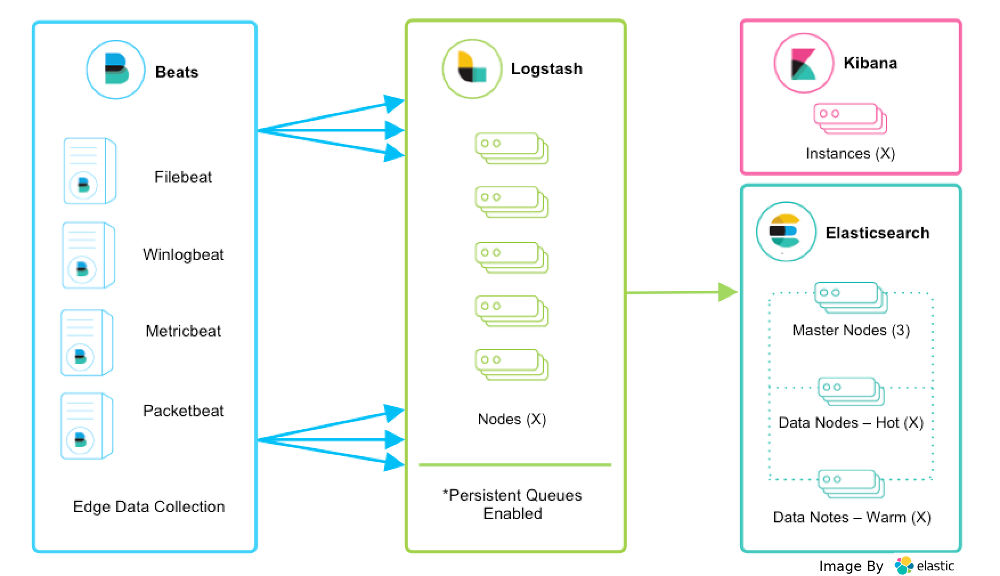
在 Ubuntu 20.04 上安装 ELK Stack
本教程旨在帮助您开始使用 ELK 堆栈。本指南不适用于生产级分布式 ELK 部署。在这里,您将了解如何安装每个 ELK 组件以及如何使它们在单个 Ubuntu 20.04 服务器上运行。在您冒险进行全面的分布式 ELK 堆栈部署之前,此单一部署服务器指南可以作为您的起点。
我假设您有一台具有 4Gb RAM 和至少 2 个 CPU 处理器核心的 Ubuntu 服务器。此外,您需要拥有有效的主机名才能访问 Kibana Web 界面。
第一步:安装必要的软件包
首先,通过运行以下命令更新发行版:
$ sudo apt update
$ sudo apt upgrade
接下来继续安装ELK安装所需的基本工具:
$ sudo apt install wget apt-transport-https curl gnupg2
由于Elasticsearch及其部分组件是用Java编写的,因此您需要安装JDK。我们将使用 OpenJDK 版本 11。
$ sudo apt install openjdk-11-jdk
检查是否安装正确:
$ java -version
openjdk version "11.0.10" 2021-01-19
OpenJDK Runtime Environment (build 11.0.10+9-Ubuntu-0ubuntu1.20.04)
OpenJDK 64-Bit Server VM (build 11.0.10+9-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
现在系统已准备好开始安装过程。
第二步:添加Elasticsearch存储库
在官方 Ubuntu 存储库中找不到 ELK 堆栈组件,因此您必须添加 Elastic(ELK 堆栈背后的公司)提供的外部存储库。该存储库允许您在 Ubuntu 环境上轻松安装和更新所有 ELK 组件。
首先,从存储库下载并添加 GPG 密钥。
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
接下来,使用以下命令将存储库添加到系统源列表中:
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
正如您所看到的,我们正在使用 ElasticSearch 的 7.x 分支,它已被证明是稳定和健壮的。所有其他 ELK 组件必须来自同一分支。
从新存储库更新包列表:
$ sudo apt update
第三步:安装Elasticsearch
您只需运行以下命令即可安装 Elasticsearch:
$ sudo apt install elasticsearch
默认情况下,会为 Elasticsearch 服务创建一个新的 systemd 服务,但不会启动。您可以使用以下命令启动服务并启用自动启动:
$ sudo systemctl start elasticsearch
$ sudo systemctl enable elasticsearch
Synchronizing state of elasticsearch.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd/systemd-sysv-install enable elasticsearch
Created symlink /etc/systemd/system/multi-user.target.wants/elasticsearch.service → /lib/systemd/system/elasticsearch.service.
您可以使用以下命令检查服务的状态:
$ sudo systemctl status elasticsearch
检查 Elasticsearch 是否正在运行的另一种方法是使用 curl 命令向端口 9200 上的本地主机发送请求。
$ curl -X GET "localhost:9200"
如果成功,您将看到输出:
{
"name" : "linux教程",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "q85s5ZOmQbeZYj4pxdV1VQ",
"version" : {
"number" : "7.11.2",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "3e5a16cfec50876d20ea77b075070932c6464c7d",
"build_date" : "2021-03-06T05:54:38.141101Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
默认情况下,Elasticsearch 侦听 TCP 端口 9200 上的本地环回地址,因此只能在本地主机上访问。当 ELK 堆栈配置在单个开发服务器上时(如本教程中假设的那样),这不是问题。

第四步:安装并配置 Kibana
Kibana 是一个开源仪表板,可让您通过精心设计的 Web 界面可视化和探索 ElasticSearch 中索引的数据。安装并正确配置 Elasticsearch 后,您可以使用以下命令安装 Kibana:
$ sudo apt install kibana
安装后,将创建一个新的 systemd 服务,您可以使用该服务启动、重新启动、停止或检查 Kibana 的状态。
您可以通过运行以下命令来启动 Kibana 服务:
$ sudo systemctl start kibana
让 Kibana 在启动时自动启动:
$ sudo systemctl enable kibana
Synchronizing state of kibana.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd/systemd-sysv-install enable kibana
Created symlink /etc/systemd/system/multi-user.target.wants/kibana.service → /etc/systemd/system/kibana.service.
Kibana 提供了一个可以通过反向代理和 HTTPS 进行保护的 Web 界面。虽然可选,但此步骤将进一步确保 ELK 堆栈安装的安全。
对于反向代理,请从官方 Ubuntu 20.04 存储库安装 Nginx。
$ sudo apt install nginx
然后创建一个新的服务器块来为 Kibana 设置反向代理。文件名可以是任何您想要的名称,但应该是描述性的。
创建以下文件:
$ sudo nano /etc/nginx/sites-available/mydomain.com
内容:
server {
listen 80;
server_name your_domain;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
将 your_domain 替换为服务器的完全限定域名(例如 www.mydomain.com)。
之后,使用以下命令启用服务器块:
$ sudo ln -s /etc/nginx/sites-available/mydomain.com /etc/nginx/sites-enabled/mydomain.com
接下来,使用 certbot 工具从 Let's Encrypt 获取证书。为此,首先安装 Certbot 和 Nginx 插件:
$ sudo apt install certbot python3-certbot-nginx
然后使用以下命令获取 Let's Encrypt 证书:
$ sudo certbot --redirect --hsts --staple-ocsp --agree-tos --email your-email --nginx -d your_domain
为了使该命令正常工作,必须使用 --email 和 -d 选项提供有效的电子邮件地址和域名。
由于 Nginx 将处理 Kibana 的外部流量,因此不要忘记在防火墙中打开 Nginx 端口:
$ sudo ufw allow 'Nginx Full'
最后,重新启动Nginx:
$ sudo systemctl reload nginx
此时,您应该能够从外部计算机通过 https://your_domain/status 访问 Kiban。
第五步:安装并配置Logstash
ELK 堆栈的这个组件允许整合来自多个源的日志数据、转换数据并重新分发数据。尽管 Logstash 可以部署为独立的日志处理工具,但它更常见地集成在功能丰富的 ELK 堆栈中。
得益于 Elastic 存储库,Logstash 的安装就像运行一样简单:
$ sudo apt install logstash
Logstash 的默认配置位于 /etc/logstash/conf.d 中。
安装Logstash后要做的第一件事是在这个配置目录中配置一个处理管道。在下面的示例中,我们配置一个非常简单的管道,由输入(数据源)和输出(数据接收器)组成,中间没有任何转换/过滤。
首先,为 Logstash 配置 Filebeat 输入,以便 Filebeat 将收集的数据传输到端口 5044 上的 Logstash。为此,创建以下文件。
$ sudo nano /etc/logstash/conf.d/02-beats-input.conf
input {
beats {
port => 5044
}
}
接下来,创建另一个配置文件来定义 Elasticsearch 的输出。
$ sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
并添加以下内容:
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
}
} else {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
}
此配置意味着 Logstash 将在 localhost:9200 上运行的 Elasticsearch 中存储 Filebeat 发送的数据。
您可以检查您创建的配置的语法是否有任何错误:
$ sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
如果一切正常,您将看到以下输出:
Configuration OK
最后启动Logstash服务并让它随系统自动启动:
$ sudo systemctl start logstash
$ sudo systemctl enable logstash
第六步:配置Filebeat
Filebeat 是 ELK 堆栈用户中最流行的 Beats 之一,旨在读取大量文件。其最常见的用例是收集日志数据并将其发送到 Logstash 或 Elasticsearch 进行存储和索引。
您可以通过运行以下命令来安装它:
$ sudo apt install filebeat
Filebeat 的配置文件位于 /etc/filebeat/filebeat/filebeat.yml 中。
使用文本编辑器打开文件:
$ sudo nano /etc/filebeat/filebeat.yml
注释掉将输出定向到 Elasticsearch 的行。
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
...
并取消对 Logstash 的注释:
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
您使用此配置所做的是将数据重定向到 Logstash 而不是 Elasticsearch。这使得可以在 Elasticsearch 饱和的情况下降低发送速率,并更好地利用 Logstash。
接下来,启用 Filebeat 系统模块。
$ sudo filebeat modules enable system
然后加载Filebeat数据解析过程。
$ sudo filebeat setup --pipelines --modules system
现在加载 Filebeat 数据索引模板。
$ sudo filebeat setup --index-management -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'.
Index setup finished.
如果想提高Filebeat与Kibana的集成度,需要在图形界面中激活该面板。为此,请禁用 Logstash 输出并启用 Elasticsearch 输出:
$ sudo filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
要应用更改,请启动 Filebeat 服务并使其随系统自动启动。
$ sudo systemctl start filebeat
$ sudo systemctl enable filebeat
现在仍然需要探索 Kibana 提供的所有功能并利用该工具。
结论
事实证明,ELK 堆栈在许多生产环境中是非常有用的解决方案,在这些环境中需要对大量分布式日志数据进行复杂的搜索和分析。希望本教程是您探索这个多功能日志分析平台的全部潜力的良好起点。