关于 Linux 上 inode 你想知道的一切

Linux 文件系统依赖于 inode。文件系统内部工作的这些重要部分经常被误解。让我们看看它们到底是什么,它们做了什么。
文件系统的元素
根据定义,文件系统需要存储文件,它们还包含目录。文件存储在目录中,这些目录可以有子目录。某处某处必须记录所有文件在文件系统中的位置、它们的名称、它们属于哪些帐户、它们拥有哪些权限等等。此信息称为元数据,因为它是描述其他数据的数据。
在 Linux ext4 文件系统中,inode 和目录结构协同工作以提供一个基础框架,用于存储每个文件和目录的所有元数据。它们使元数据可供需要它的任何人使用,无论是内核、用户应用程序还是 Linux 实用程序,例如 ls、stat 和 df。
索引节点和文件系统大小
虽然确实有一对结构,但文件系统需要的远不止于此。每个结构都有成千上万个。每个文件和目录都需要一个索引节点,因为每个文件都在一个目录中,所以每个文件也需要一个目录结构。目录结构也称为目录条目或“dentry”。
每个 inode 都有一个 inode 编号,它在一个文件系统中是唯一的。相同的索引节点号可能出现在多个文件系统中。然而,文件系统 ID 和 inode 编号结合在一起构成了一个唯一的标识符,无论您的 Linux 系统上安装了多少个文件系统。
请记住,在 Linux 中,您不会挂载硬盘或分区。您挂载分区上的文件系统,因此很容易在不知不觉中拥有多个文件系统。如果您有多个硬盘驱动器或单个驱动器上有多个分区,那么您就有多个文件系统。它们可能是相同的类型——例如,都是 ext4——但它们仍然是不同的文件系统。
所有 inode 都保存在一张表中。使用 inode 编号,文件系统可以轻松计算出该 inode 所在的 inode 表中的偏移量。你可以看到为什么 inode 中的“i”代表索引。
包含 inode 编号的变量在源代码中声明为 32 位无符号长整数。这意味着 inode 编号是一个整数值,最大大小为 2^32,计算结果为 4,294,967,295 — 超过 40 亿个 inode。
这是理论上的最大值。实际上,当文件系统以每 16 KB 文件系统容量一个 inode 的默认比率创建时,就确定了 ext4 文件系统中 inode 的数量。目录结构是在使用文件系统时即时创建的,因为文件和目录是在文件系统中创建的。
有一个命令可以用来查看计算机文件系统中有多少 inode。 df 命令的 -i(索引节点)选项指示它以索引节点数显示其输出。
我们要查看第一个硬盘驱动器第一个分区上的文件系统,因此我们键入以下内容:
df -i /dev/sda1
输出给了我们:
- 文件系统:报告的文件系统。
- Inodes:此文件系统中的 inode 总数。
- IUsed:正在使用的 inode 数量。
- IFree:可供使用的剩余 inode 数。
- IUse%:已使用 inode 的百分比。
- 挂载于:此文件系统的挂载点。
我们已经使用了该文件系统中 10% 的索引节点。文件以磁盘块的形式存储在硬盘驱动器上。每个索引节点都指向存储它们所代表的文件内容的磁盘块。如果您有数百万个小文件,您可能会在用完硬盘空间之前用完 inode。然而,这是一个很难遇到的问题。
过去,一些将电子邮件消息存储为离散文件(这会迅速导致大量小文件集合)的邮件服务器存在此问题。不过,当这些应用程序将其后端更改为数据库时,问题就解决了。一般的家庭系统不会用完 inode,这也是因为,使用 ext4 文件系统,如果不重新安装文件系统就无法添加更多 inode。
要查看文件系统上磁盘块的大小,可以使用带有 --getbsz(获取块大小)选项的 blockdev 命令:
sudo blockdev --getbsz /dev/sda
块大小为 4096 字节。
让我们使用 -B(块大小)选项指定 4096 字节的块大小并检查常规磁盘使用情况:
df -B 4096 /dev/sda1
这个输出告诉我们:
- 文件系统:我们报告的文件系统。
- 4K-blocks:此文件系统中 4 KB 块的总数。
- 已用:正在使用的 4K 块数。
- 可用:可供使用的剩余 4 KB 块的数量。
- Use%:已使用的 4 KB 块的百分比。
- 挂载于:此文件系统的挂载点。
在我们的示例中,文件存储(以及 inode 和目录结构的存储)使用了该文件系统上 28% 的空间,以 10% 的 inode 为代价,所以我们的状态很好。
索引节点元数据
要查看文件的 inode 编号,我们可以使用 ls 和 -i (inode)选项:
ls -i geek.txt
这个文件的 inode 号是 1441801,所以这个 inode 保存了这个文件的元数据,传统上,还有指向文件在硬盘驱动器上所在的磁盘块的指针。如果文件是碎片化的、非常大的或两者兼而有之,则 inode 指向的某些块可能包含指向其他磁盘块的进一步指针。并且其中一些其他磁盘块也可能包含指向另一组磁盘块的指针。这克服了 inode 大小固定并且能够保存有限数量的指向磁盘块的指针的问题。
该方法已被使用“范围”的新方案所取代。这些记录用于存储文件的每组连续块的开始和结束块。如果文件未分片,则只需存储第一个块和文件长度。如果文件是碎片化的,则必须存储文件每个部分的第一个和最后一个块。这种方法(显然)更有效。
如果您想查看您的文件系统是否使用磁盘块指针或盘区,您可以查看 inode 内部。为此,我们将使用带有 -R(请求)选项的 debugfs 命令,并将感兴趣的文件的 inode 传递给它。这会要求 debugfs 使用其内部的“stat”命令来显示 inode 的内容。因为 inode 编号仅在文件系统中是唯一的,所以我们还必须告诉 debugfs inode 所在的文件系统。
下面是这个示例命令的样子:
sudo debugfs -R "stat <1441801>" /dev/sda1
如下所示,debugfs 命令从 inode 中提取信息并在 less 中呈现给我们:
我们看到了以下信息:
- Inode:我们正在查看的 inode 的编号。
- 类型:这是一个普通文件,不是目录或符号链接。
- Mode:八进制的文件权限。
- 标志:代表不同特性或功能的指示符。 0x80000 是“范围”标志(更多内容见下文)。
- 生成:当有人通过网络连接访问远程文件系统时,网络文件系统 (NFS) 会使用它,就好像它们安装在本地机器上一样。 inode 和世代号用作文件句柄的一种形式。
- 版本:索引节点版本。
- 用户:文件的所有者。
- 组:文件的组所有者。
- 项目:应始终为零。
- 大小:文件的大小。
- File ACL:文件访问控制列表。这些旨在允许您向不属于所有者组的人提供受控访问权限。
- 链接数:文件的硬链接数。
- Blockcount:分配给该文件的硬盘驱动器空间量,以 512 字节块为单位。我们的文件已经分配了其中的八个,即 4,096 字节。因此,我们的 98 字节文件位于一个 4,096 字节的磁盘块中。
- 碎片:该文件没有碎片。 (这是一个过时的标志。)
- Ctime:文件的创建时间。
- Atime:上次访问此文件的时间。
- Mtime:上次修改此文件的时间。
- Crtime:文件的创建时间。
- 额外 inode 字段的大小:ext4 文件系统引入了在格式化时分配更大磁盘 inode 的能力。该值是 inode 使用的额外字节数。此额外空间还可用于满足未来对新内核的要求或存储扩展属性。
- Inode checksum:此 inode 的校验和,可以检测 inode 是否已损坏。
- Extents:如果正在使用范围(在 ext4 上,默认情况下是),关于文件磁盘块使用情况的元数据有两个数字,表示每个部分的开始和结束块一个碎片化的文件。这比存储文件的每个部分占用的每个磁盘块更有效。我们只有一个范围,因为我们的小文件位于此块偏移量处的一个磁盘块中。
文件名在哪里?
我们现在有很多关于文件的信息,但是,正如您可能已经注意到的,我们没有得到文件名。这是目录结构发挥作用的地方。在 Linux 中,就像文件一样,目录也有一个 inode。但是,目录 inode 不是指向包含文件数据的磁盘块,而是指向包含目录结构的磁盘块。
与 inode 相比,目录结构包含有关文件的有限信息。它只保存文件的索引节点号、名称和名称的长度。
inode 和目录结构包含您(或应用程序)需要了解的有关文件或目录的所有信息。目录结构位于目录磁盘块中,因此我们知道文件所在的目录。目录结构为我们提供了文件名和索引节点号。 inode 告诉我们关于文件的所有其他信息,包括时间戳、权限以及在文件系统中的何处可以找到文件数据。
目录索引节点
您可以像查看文件一样轻松地查看目录的 inode 编号。
在下面的示例中,我们将使用 ls 和 -l(长格式)、-i(inode)和 -d(目录)选项,查看work目录:
ls -lid work/
因为我们使用了 -d(目录)选项,ls 报告目录本身,而不是其内容。该目录的 inode 是 1443016。
要对 home 目录重复上述操作,我们键入以下内容:
ls -lid ~
home 目录的 inode 是 1447510,work 目录在 home 目录中。现在,让我们看一下 work 目录的内容。我们将使用 -a(全部)选项,而不是 -d(目录)选项。这将向我们显示通常隐藏的目录条目。
我们键入以下内容:
ls -lia work/
因为我们使用了 -a(全部)选项,所以会显示单点 (.) 和双点 (..) 条目。这些条目代表目录本身(单点)及其父目录(双点)。
如果您查看单点条目的 inode 编号,您会发现它是 1443016 — 与我们发现 work 目录的 inode 编号时得到的 inode 编号相同。此外,双点条目的 inode 编号与 home 目录的 inode 编号相同。
这就是为什么您可以使用 cd .. 命令在目录树中向上移动一个级别。同样,当您在应用程序或脚本名称前加上 ./ 时,您让 shell 知道从哪里启动应用程序或脚本。
索引节点和链接
正如我们所介绍的,在文件系统中拥有一个格式良好且可访问的文件需要三个组件:文件、目录结构和索引节点。文件是存储在硬盘上的数据,目录结构包含文件的名称及其索引节点号,索引节点包含文件的所有元数据。
符号链接是看起来像文件的文件系统条目,但它们实际上是指向现有文件或目录的快捷方式。让我们看看他们是如何管理的,以及如何使用这三个元素来实现这一目标。
假设我们有一个包含两个文件的目录:一个是脚本,另一个是应用程序,如下所示。
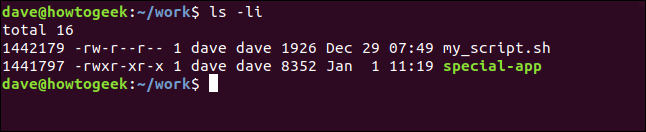
我们可以使用 ln 命令和 -s(符号)选项创建到脚本文件的软链接,如下所示:
ls -s my_script geek.sh
我们创建了一个指向 my_script.sh 的链接,名为 geek.sh。我们可以键入以下内容并使用 ls 查看这两个脚本文件:
ls -li *.sh
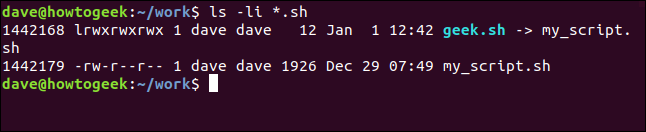
geek.sh 条目显示为蓝色。权限标志的第一个字符是链接的“l”,-> 指向 my_script.sh。所有这些都表明 geek.sh 是一个链接。
如您所料,这两个脚本文件具有不同的 inode 编号。不过,可能更令人惊讶的是软链接 geek.sh 没有与原始脚本文件相同的用户权限。事实上,geek.sh 的权限更为宽松——所有用户都拥有完全权限。
geek.sh 的目录结构包含链接的名称及其索引节点。当您尝试使用该链接时,它的 inode 被引用,就像一个普通文件一样。链接 inode 将指向一个磁盘块,但磁盘块不包含文件内容数据,而是包含原始文件的名称。文件系统重定向到原始文件。
我们将删除原始文件,并查看当我们键入以下内容以查看 geek.sh 的内容时会发生什么:
rm my_script.shcat geek.sh
符号链接已损坏,重定向失败。
我们现在键入以下内容以创建到应用程序文件的硬链接:
ln special-app geek-app
要查看这两个文件的索引节点,我们键入以下内容:
ls -li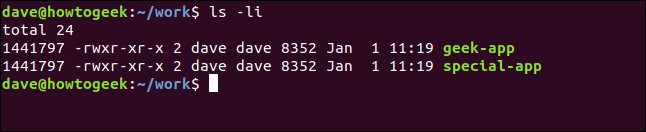
两者看起来都像普通文件。 geek-app 没有任何迹象表明它是 geek.sh 的 ls 列表中的链接。此外,geek-app 具有与原始文件相同的用户权限。然而,令人惊讶的是这两个应用程序具有相同的 inode 编号:1441797。
geek-app 的目录条目包含名称“geek-app”和一个 inode 编号,但它与原始文件的 inode 编号相同。因此,我们有两个名称不同的文件系统条目,它们都指向同一个 inode。事实上,任意数量的项目都可以指向同一个 inode。
我们将键入以下内容并使用 stat 程序查看目标文件:
stat special-app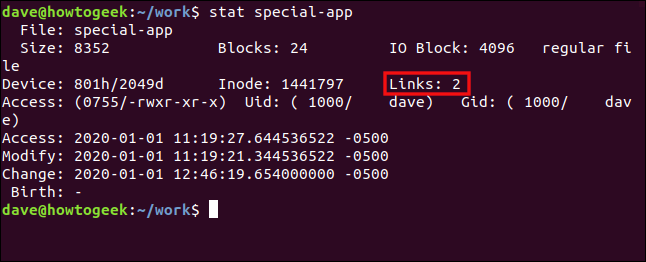
我们看到有两个硬链接指向这个文件。这存储在 inode 中。
在以下示例中,我们删除了原始文件并尝试使用带有秘密、安全密码的链接:
rm special-app./geek-app correcthorsebatterystaple
令人惊讶的是,应用程序按预期运行,但如何运行呢?它之所以有效,是因为当您删除文件时,inode 可以自由重用。目录结构被标记为索引节点号为零,然后磁盘块可用于存储在该空间中的另一个文件。
但是,如果指向 inode 的硬链接数大于 1,则硬链接数减 1,并且删除文件的目录结构的 inode 号设置为零。硬盘和 inode 上的文件内容对于现有的硬链接仍然可用。
我们将键入以下内容并再次使用 stat — 这次是在 geek-app 上:
stat geek-app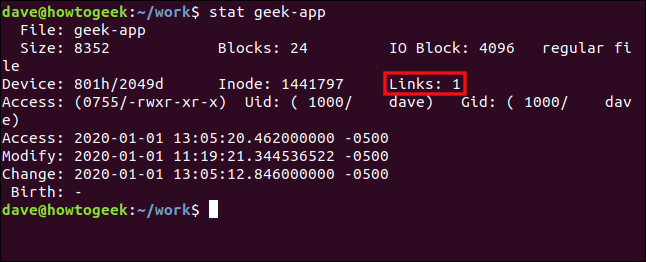
这些详细信息是从与之前的 stat 命令相同的 inode (1441797) 中提取的。链接数减少了一个。
因为我们只有一个指向该 inode 的硬链接,所以如果我们删除 geek-app,它会真正删除该文件。文件系统将释放 inode 并用零 inode 标记目录结构。然后,新文件可以覆盖硬盘上的数据存储。
索引节点开销
这是一个整洁的系统,但有开销。要读取文件,文件系统必须执行以下所有操作:
- 找到正确的目录结构
- 读取inode号
- 找到正确的索引节点
- 读取inode信息
- 遵循索引节点链接或相关磁盘块的范围
- 读取文件数据
如果数据是不连续的,则需要更多的跳跃。
想象一下 ls 执行许多文件的长格式文件列表必须完成的工作。为了获取生成输出所需的信息,ls 有很多来回。
当然,加速文件系统访问是 Linux 尝试尽可能多地进行抢占式文件缓存的原因。这有很大帮助,但有时——与任何文件系统一样——开销会变得很明显。
现在你会知道为什么了。
| Linux Commands | ||
| Files | tar · pv · cat · tac · chmod · grep · diff · sed · ar · man · pushd · popd · fsck · testdisk · seq · fd · pandoc · cd · $PATH · awk · join · jq · fold · uniq · journalctl · tail · stat · ls · fstab · echo · less · chgrp · chown · rev · look · strings · type · rename · zip · unzip · mount · umount · install · fdisk · mkfs · rm · rmdir · rsync · df · gpg · vi · nano · mkdir · du · ln · patch · convert · rclone · shred · srm · scp · gzip · chattr · cut · find · umask · wc | |
| Processes | alias · screen · top · nice · renice · progress · strace · systemd · tmux · chsh · history · at · batch · free · which · dmesg · chfn · usermod · ps · chroot · xargs · tty · pinky · lsof · vmstat · timeout · wall · yes · kill · sleep · sudo · su · time · groupadd · usermod · groups · lshw · shutdown · reboot · halt · poweroff · passwd · lscpu · crontab · date · bg · fg · pidof · nohup · pmap | |
| Networking | netstat · ping · traceroute · ip · ss · whois · fail2ban · bmon · dig · finger · nmap · ftp · curl · wget · who · whoami · w · iptables · ssh-keygen · ufw · arping · firewalld |
RELATED: Best Linux Laptops for Developers and Enthusiasts