在 Linux 服务器中监控的 6 个关键性能指标
这个由 4 部分组成的系列将解释要在 Linux 服务器中监控的六个关键性能指标。到本系列结束时,您将了解 Linux 系统中需要注意哪些因素会影响整体系统性能,以及它们的相对重要性。
您的 Linux 服务器是否运行缓慢或托管在其上的应用程序是否显示出意外行为或性能低下的迹象? Linux 服务器中的许多因素会影响其整体性能或托管在其上的应用程序的性能。
但是您需要跟踪一些关键指标,它们可能会影响最关键的事情,例如响应时间或进程的执行时间、吞吐量——服务器在给定时间内可以完成的工作总量,等等。
让我们看看本系列第一部分中的前两个关键性能指标。
1. Linux CPU 利用率
作为系统的大脑,正常运行的 CPU 是 Linux 服务器或任何计算机的关键部分。因此,CPU 使用情况是 Linux 服务器中要跟踪的重要方面之一,用于根据吞吐量衡量系统性能。
有多种基于命令行和图形用户界面的工具可用于监控 Linux 系统上的 CPU 使用情况,例如 htop 等。
Glances – Linux 监控工具
Glances 是一个开源实时监控实用程序,可以监控 Linux 系统的多个方面,例如 CPU、内存、磁盘和网络使用情况。
要在您的 Linux 发行版上安装 glances,请运行:
$ sudo apt install glances [On Debian, Ubuntu and Mint]
$ sudo yum install glances [On RHEL/CentOS/Fedora and Rocky/AlmaLinux]
$ sudo emerge -a sys-process/glances [On Gentoo Linux]
$ sudo apk add glances [On Alpine Linux]
$ sudo pacman -S glances [On Arch Linux]
$ sudo zypper install glances [On OpenSUSE]
以下是 Debian Linux 服务器上的 glances 监控工具的一部分屏幕截图,显示了 CPU 利用率统计信息。
# glances
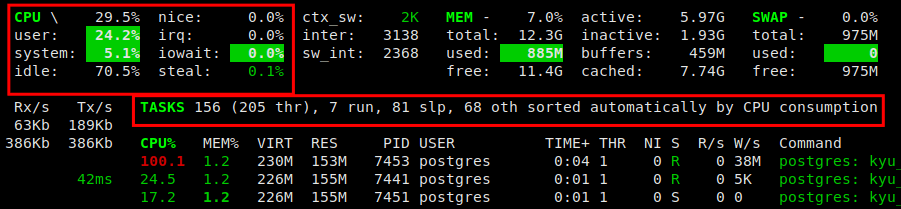
这里的整体 CPU 使用率为 29.5%,用户空间进程或应用程序使用了更多的 CPU 时间。它显示任务总数 (156)、正在运行的任务数 (7)、处于睡眠模式的任务数 (81) 等。它还默认显示 CPU 消耗的进程列表。
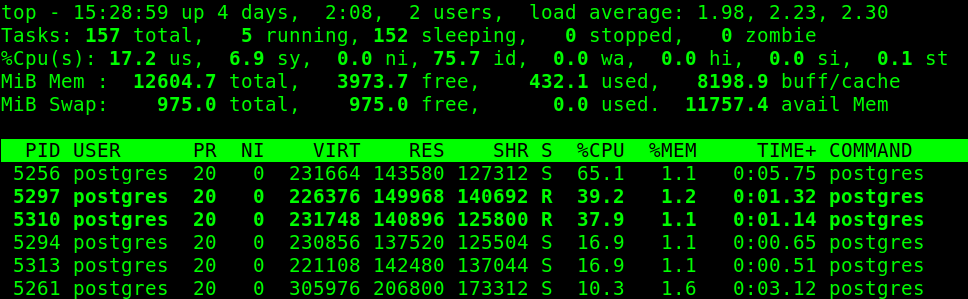
顶部 - 监控 Linux 进程
top 命令提供 Linux 系统中所有正在运行的进程以及 CPU 和内存利用率的动态实时视图。
# top
htop——Linux 进程查看器
htop 是一个交互式 Linux 系统进程查看器和进程管理器,它通过系统上的 CPU 和内存使用情况显示所有正在运行的进程的信息。
要在您的 Linux 发行版上安装 htop,请运行:
$ sudo apt install htop [On Debian, Ubuntu and Mint]
$ sudo yum install htop [On RHEL/CentOS/Fedora and Rocky/AlmaLinux]
$ sudo emerge -a sys-process/htop [On Gentoo Linux]
$ sudo apk add htop [On Alpine Linux]
$ sudo pacman -S htop [On Arch Linux]
$ sudo zypper install htop [On OpenSUSE]
下面是一个htop监控工具的截图,它显示了一个按CPU使用率划分的正在运行的进程列表。
# htop
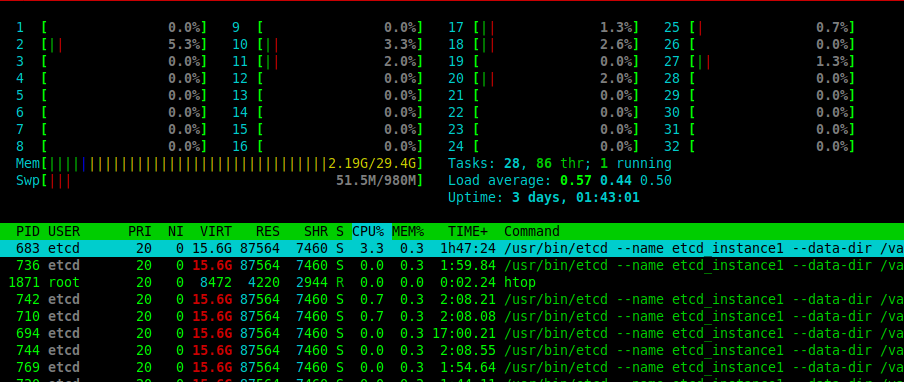
根据您在前面的屏幕截图中看到的数字,CPU 使用指标分为三个主要类别或状态:
- user – 表示用户空间进程使用的 CPU 时间百分比。
- system – 显示内核使用的 CPU 时间百分比。
- idle – 显示未被积极使用的 CPU 时间百分比。
此外,还有以下 CPU 子状态:
- nice – 是用户状态的子集,表示具有正 nice 值(比其他进程的调度优先级低)的用户级进程占用的 CPU 时间百分比。
- irq 或 hi – 显示用于服务硬件中断的 CPU 时间百分比。
- softirq 或 si – 显示用于服务软件中断的 CPU 时间百分比。
- iowait 或 wa – 空闲状态的一个子集,显示等待 I/O 操作(例如读写磁盘)所花费的 CPU 时间百分比.
- steal – 显示管理程序中的虚拟 CPU 非自愿地等待物理 CPU 处理时间所占用的 CPU 时间百分比。
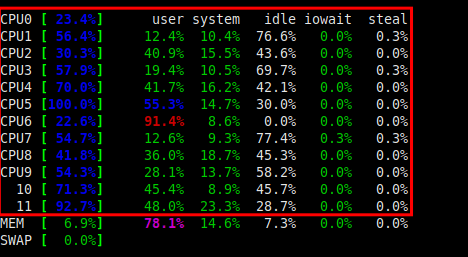
监控 Linux CPU 核心利用率
如果您的服务器有多个处理器(有时称为多核系统),您还可以监控每个内核的利用率。在 glances 中,只需按 1 即可获得如下一个屏幕截图所示的视图。
您还可以运行以下命令来查找服务器中的处理器总数:
# cat /proc/cpuinfo | grep ^processor
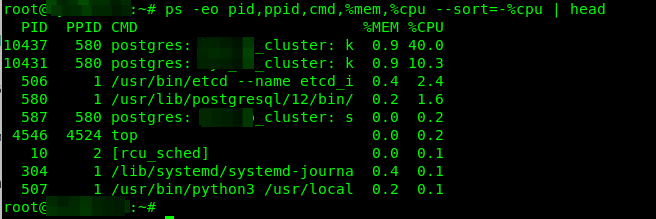
要按 CPU 使用率查找运行最多的进程,请运行以下 ps 命令:
# ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%cpu | head
您可能还喜欢:
- Cpustat – 通过在 Linux 中运行进程来监控 CPU 利用率
- 如何使用 Kill、Pkill 和 Killall 杀死 Linux 进程
- 如何在 Linux 中限制进程的时间和内存使用
- 在 Linux 上获取 CPU 信息的 9 个有用命令
2.监控Linux系统CPU负载
CPU 负载是正在使用或想要使用 CPU 时间的进程/线程数。在 Linux 上,不仅是可运行的任务(不被任何东西阻塞,准备在 CPU 上运行或在运行队列中等待),还有处于不可中断睡眠状态的任务,例如等待 I/O 操作的进程完成或其他事情。
它与我们上面介绍的 CPU 使用率不同。平均负载是一段时间内的平均系统负载,在 Linux 中通常是一分钟、五分钟和十五分钟。如果平均负载为 0.0,则您的系统处于空闲状态。
如果您有一台 12 核的多核服务器,平均负载为 8.32,如下面的屏幕截图所示,这意味着 CPU 在容量不足的情况下工作,它可以承受更多负载。如果平均负载为 12,则意味着满容量。
# glances

另一方面,大于 CPU 内核总数的平均负载表明进程正在排队——负载正在增加。以下屏幕截图显示了一个不健康的系统,它已过载。
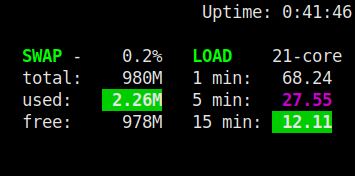
请记住,如果 1 分钟的平均值高于 5 分钟或 15 分钟的平均值,就像前面示例中的情况(68.24、27.55、12.11),则表明 CPU 负载正在飙升。但是,如果 1 分钟的平均值低于 5 或 15 分钟的平均值,则负载正在下降。
您还可以使用 uptime 或 w 命令 查看负载平均值。在这个例子中,负载在增加。
# uptime
OR
# w
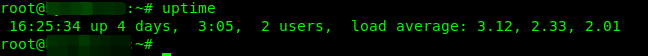
高 CPU 使用率或 CPU 负载的原因
导致 CPU 高或极高的一些最常见原因包括在同一台服务器上运行多个 CPU 密集型应用程序/服务(资源规格低),以及旨在反复自我复制以耗尽系统资源的恶意软件。当流量很高时,流媒体和游戏应用程序也会导致极高的 CPU 使用率和 CPU 负载。
此外,DoS 或 DDoS 攻击可能会触发对托管应用程序的大量连接和请求,需要 CPU 进行额外的复杂计算。应用程序中的错误或未优化的代码有时会导致无限循环,从而耗尽可用的 CPU 时间。
注意:CPU 使用率较低但系统或 CPU 负载可能很高。这种情况可能是由于大量线程处于不间断睡眠状态加上正常的 CPU 需求造成的。
您可能还喜欢:
- 保护 Linux 系统的基本安全提示
- 如何提高 Linux 系统的安全性
- 在 Linux 中防止 SSH 暴力登录攻击的 5 个最佳实践
- 7 个对初学者有用的 Linux 安全特性和工具
高 CPU 使用率或 CPU 负载的影响
如果您的系统过载,CPU 密集型应用程序可能会冻结或崩溃,其他正在运行的应用程序可能会变慢并最终停止响应用户输入;备份和系统警报等自动化作业可能会失败,应用程序可能会以蜗牛般的速度打开或根本无法打开,等等。
最大限度地减少高 CPU 使用率和 CPU 过载
以下是解决 Linux 服务器中高 CPU 使用率或系统负载的一些方法:
- 快速添加更多 CPU,尤其是在虚拟环境中。
- 必要时重新启动 CPU 密集型应用程序。
- 停止/禁用未使用的服务/应用程序。
- 检查用户应用程序中可能导致无限循环的错误或未优化的代码。
- 限制网络服务器、应用程序服务器和数据库系统中允许的连接或请求数量,以减轻 DoS 或 DDoS 攻击。
- 如果服务器开始冻结,必要时重新启动服务器。
- 使用脚本或监控应用程序设置在 CPU 使用率异常高时触发的系统警报。
目前为止就这样了。在本系列的下一部分中,我们将介绍如何监控 Linux 服务器上的内存利用率。在那之前,请留在我们身边。