如何在 Ubuntu 22.04 上安装 Apache Hadoop
本教程适用于这些操作系统版本
- Ubuntu 22.04(Jammy Jellyfish)
- Ubuntu 20.04(Focal Fossa)
在此页
- 先决条件
- 安装 Java OpenJDK
- 设置用户和无密码 SSH 身份验证
- 下载 Hadoop
- 设置 Hadoop 环境变量
- 设置 Apache Hadoop 集群:伪分布式模式
- 设置 NameNode 和 DataNode
- 纱线经理
Apache Hadoop 是一个用于处理和存储大数据的开源框架。在当今的行业中,Hadoop 成为大数据的标准框架。 Hadoop 旨在运行在具有数百甚至数千台集群计算机或专用服务器的分布式系统上。考虑到这一点,Hadoop 可以处理结构化和非结构化数据的高容量和复杂性的大型数据集。
每个 Hadoop 部署都包含以下组件:
- Hadoop Common:支持其他 Hadoop 模块的通用实用程序。
- Hadoop 分布式文件系统 (HDFS):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
- Hadoop YARN:作业调度和集群资源管理框架。
- Hadoop MapReduce:一种基于 YARN 的系统,用于并行处理大型数据集。
在本教程中,我们将在 Ubuntu 22.04 服务器上安装最新版本的 Apache Hadoop。 Hadoop 安装在单节点服务器上,我们创建 Hadoop 部署的伪分布式模式。
先决条件
要完成本指南,您需要满足以下要求:
- Ubuntu 22.04 服务器 - 此示例使用主机名 hadoop 服务器和 IP 地址 192.168.5.100 的 Ubuntu 服务器。
- 具有 sudo/root 管理员权限的非 root 用户。
安装 Java OpenJDK
Hadoop是Apache软件基金会下的一个庞大的项目,主要是用Java编写的。在撰写本文时,hadoop 的最新版本是 v3.3,4,它与 Java v11 完全兼容。
Java OpenJDK 11 默认在 Ubuntu 存储库中可用,您将通过 APT 安装它。
首先,运行以下 apt 命令来更新和刷新 Ubuntu 系统上的包列表/存储库。
sudo apt update现在通过下面的 apt 命令安装 Java OpenJDK 11。在 Ubuntu 22.04 存储库中,包 default-jdk 指的是 Java OpenJDK v11。
sudo apt install default-jdk出现提示时,输入 y 确认并按 ENTER 继续。 Java OpenJDK 安装将开始。
安装 Java 后,运行以下命令来验证 Java 版本。您应该在 Ubuntu 系统上安装 Java OpenJDK 11。
java -version
现在已经安装了 Java OpebnJDK,然后您将使用无密码 SSH 身份验证设置一个新用户,该用户将用于运行 hadoop 进程和服务。
设置用户和无密码 SSH 身份验证
Apache Hadoop 需要 SSH 服务才能在系统上运行。 hadoop 脚本将使用它来管理远程服务器上的远程 hadoop 守护进程。在此步骤中,您将创建一个新用户,用于运行 hadoop 进程和服务,然后设置无密码 SSH 身份验证。
如果您的系统上没有安装 SSH,请运行下面的 apt 命令来安装 SSH。 pdsh 包是一个多线程远程 shell 客户端,允许您以并行模式在多个主机上执行命令。
sudo apt install openssh-server openssh-client pdsh现在运行以下命令创建一个新用户 hadoop 并为 hadoop 用户设置密码。
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoop输入hadoop 用户的新密码并重复密码。
接下来,通过下面的 usermod 命令将 hadoop 用户添加到 sudo 组。这允许用户 hadoop 执行 sudo 命令。
sudo usermod -aG sudo hadoop现在 hadoop 用户已创建,请通过以下命令登录到 hadoop 用户。
su - hadoop登录后,您的提示将变成这样:“[email ”。
接下来,运行以下命令生成 SSH 公钥和私钥。当提示为密钥设置密码时,按 ENTER 跳过。
ssh-keygen -t rsaSSH 密钥现在生成到 ~/.ssh 目录。 id_rsa.pub 是 SSH 公钥,id_rsa 文件是私钥。
您可以通过以下命令验证生成的 SSH 密钥。
ls ~/.ssh/接下来,运行以下命令将 SSH 公钥 id_rsa.pub 复制到 authorized_keys 文件并将默认权限更改为 600。
在 ssh 中,authorized_keys\ 文件是您存储 ssh 公钥的地方,它可以是多个公钥。任何拥有存储在文件 authorized_keys 中的公钥并拥有正确的私钥将能够以 hadoop 用户身份连接到服务器,无需密码。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
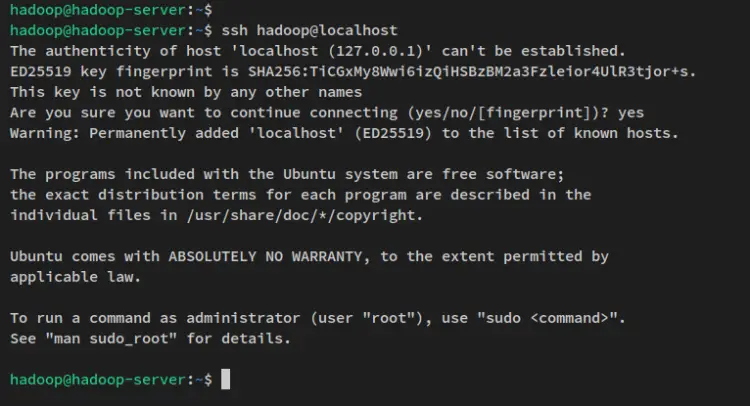
SSH 无密码配置完成后,您可以通过下面的 ssh 命令连接到本地机器来进行验证。
ssh localhost输入 yes 确认并添加 SSH 指纹,您将无需密码验证即可连接到服务器。
现在已经创建了 hadoop 用户并配置了无密码 SSH 身份验证,然后您将通过下载 hadoop 二进制包来检查 hadoop 安装。
下载 Hadoop
创建新用户并配置无密码 SSH 身份验证后,您现在可以下载 Apache Hadoop 二进制包并为其设置安装目录。在此示例中,您将下载 hadoop v3.3.4,目标安装目录将是 /usr/local/hadoop 目录。
运行以下 wget 命令将 Apache Hadoop 二进制包下载到当前工作目录。您应该在当前工作目录中获取文件 hadoop-3.3.4.tar.gz。
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz接下来,通过下面的 tar 命令提取 Apache Hadoop 包 hadoop-3.3.4.tar.gz。然后,将提取的目录移动到/usr/local/hadoop。
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoop最后,将hadoop安装目录/usr/local/hadoop的所有权更改为用户hadoop和组hadoop。
sudo chown -R hadoop:hadoop /usr/local/hadoop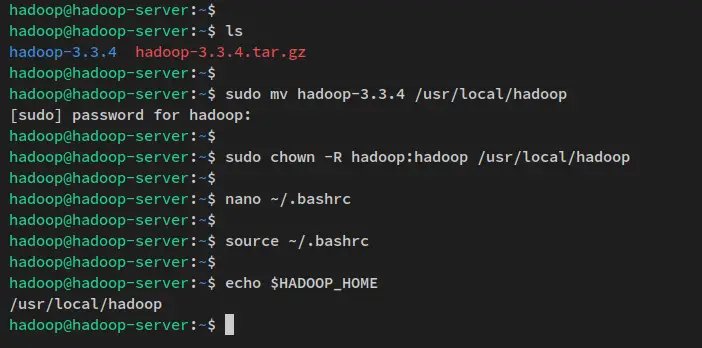
在这一步中,您下载了 Apache Hadoop 二进制包并配置了 hadoop 安装目录。考虑到这一点,您现在可以开始配置 hadoop 安装。
设置 Hadoop 环境变量
通过下面的 nano 编辑器命令打开配置文件 ~/.bashrc。
nano ~/.bashrc将以下行添加到文件中。请务必将以下行放在行尾。
# Hadoop environment variables
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"完成后保存文件并退出编辑器。
接下来,运行以下命令以在文件 ~/.bashrc 中应用新更改。
source ~/.bashrc执行命令后,将应用新的环境变量。您可以通过以下命令检查每个环境变量来进行验证。你应该得到每个环境变量的输出。
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTS接下来,您还将在 hadoop-env.sh 脚本中配置 JAVA_HOME 环境变量。
使用以下 nano 编辑器命令打开文件 hadoop-env.sh。 hadoop-env.sh 文件位于$HADOOP_HOME 目录中,该目录指的是hadoop 安装目录/usr/local/hadoop。
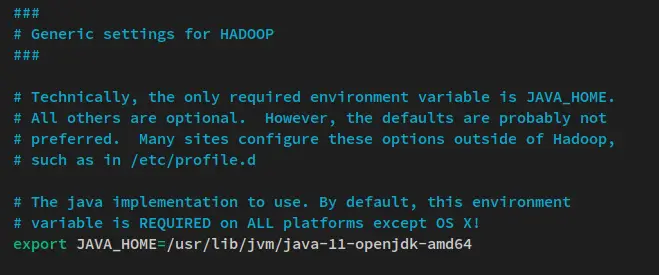
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh取消注释 JAVA_HOME 环境行并将值更改为 Java OpenJDK 安装目录 /usr/lib/jvm/java-11-openjdk-amd64。
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64完成后保存文件并退出编辑器。
使用环境变量配置,运行以下命令来验证系统上的 hadoop 版本。您应该会看到系统上安装了 Apache Hadoop 3.3.4。
hadoop version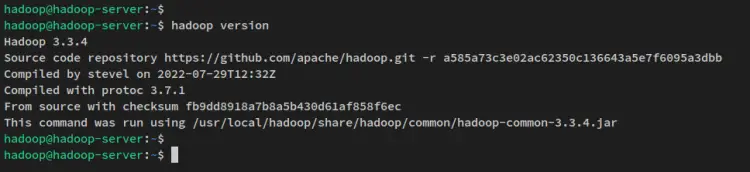
此时,您已准备好设置和配置 hadoop 集群,该集群可以以多种方式部署。
搭建 Apache Hadoop 集群:伪分布式模式
在 hadoop 中,您可以通过三种不同的模式创建集群:
- 本地模式(独立)- 默认 hadoop 安装,作为单个 Java 进程和非分布式模式运行。有了这个,你就可以轻松调试hadoop进程了。
- 伪分布式模式 - 这允许您以分布式模式运行 hadoop 集群,即使只有一个节点/服务器。在这种模式下,hadoop 进程将在单独的 Java 进程中运行。
- 完全分布式模式 - 具有多个甚至数千个节点/服务器的大型 hadoop 部署。如果你想在生产中运行 hadoop,你应该在完全分布式模式下使用 hadoop。
在此示例中,您将在单个 Ubuntu 服务器上设置一个采用伪分布式模式的 Apache Hadoop 集群。为此,您将更改一些 hadoop 配置:
- core-site.xml - 这将用于为 hadoop 集群定义 NameNode。
- hdfs-site.xml - 将使用此配置来定义 hadoop 集群上的 DataNode。
- mapred-site.xml - hadoop 集群的 MapReduce 配置。
- yarn-site.xml - hadoop 集群的 ResourceManager 和 NodeManager 配置。
设置NameNode和DataNode
首先,您将为 hadoop 集群设置 NameNode 和 DataNode。
使用以下 nano 编辑器打开文件 $HADOOP_HOME/etc/hadoop/core-site.xml。
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml将以下行添加到文件中。请务必更改 NameNode IP 地址,或者您可以将其替换为 0.0.0.0,这样 NameNode 将在所有接口和 IP 地址上运行。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.5.100:9000</value>
</property>
</configuration>完成后保存文件并退出编辑器。
接下来,运行以下命令来创建将用于 hadoop 集群上 DataNode 的新目录。然后,将DataNode 目录的所有权更改为hadoop 用户。
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs之后,使用以下 nano 编辑器命令打开文件 $HADOOP_HOME/etc/hadoop/hdfs-site.xml。
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml将以下配置添加到文件中。在此示例中,您将在单个节点中设置 hadoop 集群,因此您必须将 dfs.replication 值更改为 1。此外,您必须指定将用于 DataNode 的目录。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>完成后保存文件并退出编辑器。
配置好 NameNode 和 DataNode 后,运行以下命令格式化 hadoop 文件系统。
hdfs namenode -format您将收到如下输出:
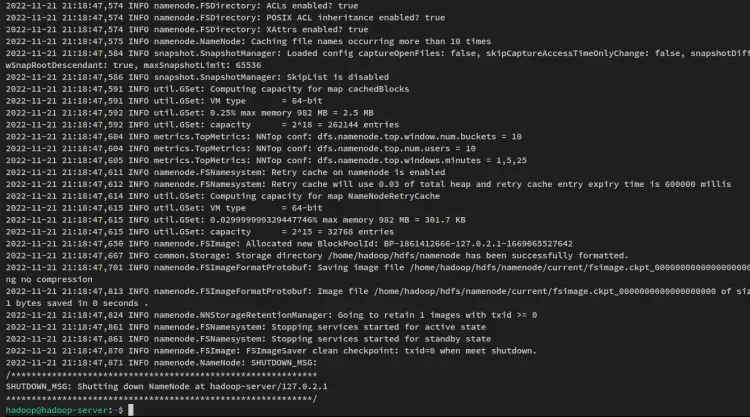
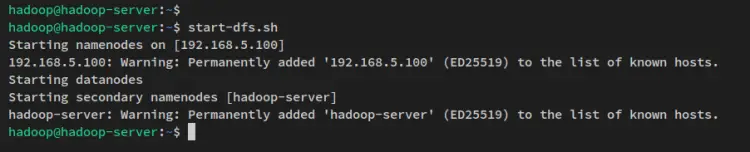
接下来,通过以下命令启动 NameNode 和 DataNode。 NameNode 将在您在文件 core-site.xml 中配置的服务器 IP 地址上运行。
start-dfs.sh你会看到这样的输出:
现在 NameNode 和 DataNode 正在运行,您将通过 Web 界面验证这两个进程。
hadoop NameNode Web 界面运行端口 9870。因此,打开您的 Web 浏览器并访问服务器 IP 地址后跟端口 9870(即:http://192.168.5.100:9870/)。
您现在应该获得如下屏幕截图所示的页面 - NameNode 当前处于活动状态。
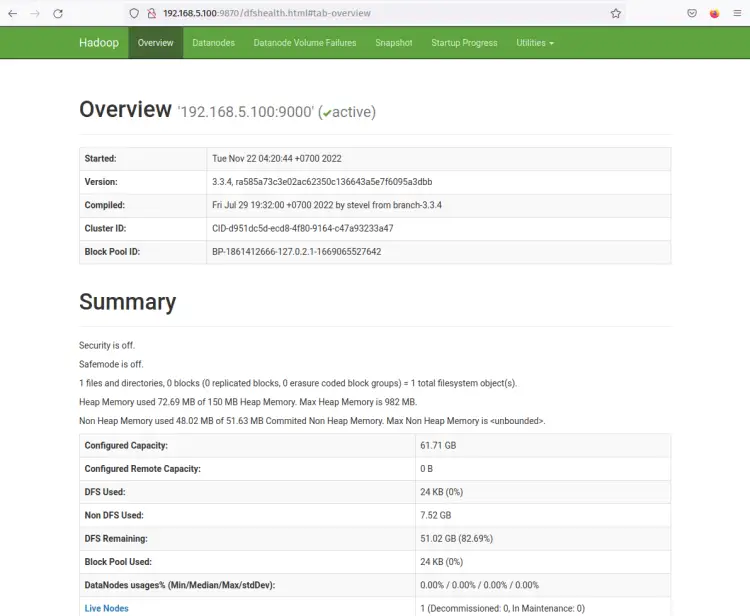
现在点击 Datanodes 菜单,你应该得到当前在 hadoop 集群上活动的 DataNode。以下屏幕截图确认 DataNode 正在 hadoop 集群上的端口 9864 上运行。
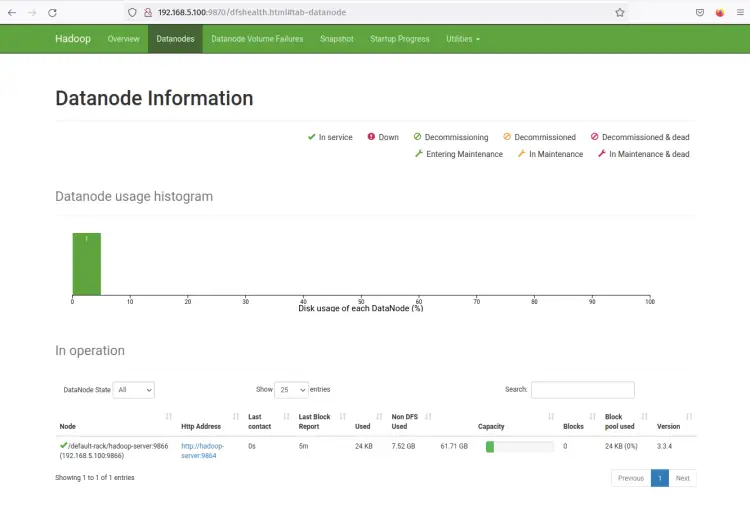
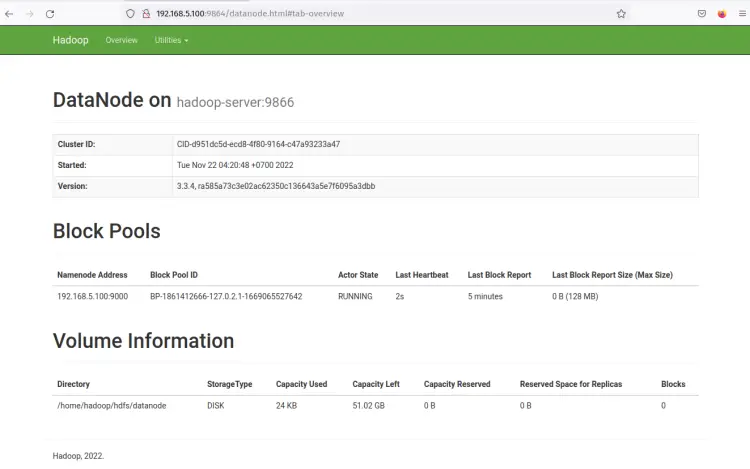
单击 DataNode Http Address,您应该会看到一个包含 DataNode 详细信息的新页面。以下屏幕截图确认 DataNode 正在使用卷目录 /home/hadoop/hdfs/datanode 运行。
随着 NameNode 和 DataNode 的运行,接下来您将在 Yarn 管理器(Yet Another ResourceManager 和 NodeManager)上设置并运行 MapReduce。
纱线经理
要以伪分布式模式在 Yarn 上运行 MapReduce,您需要对配置文件进行一些更改。
使用以下 nano 编辑器命令打开文件 $HADOOP_HOME/etc/hadoop/mapred-site.xml。
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml将以下行添加到文件中。请务必将 mapreduce.framework.name 更改为 yarn。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>完成后保存文件并退出编辑器。
接下来,使用以下 nanoe 编辑器命令打开 Yarn 配置 $HADOOP_HOME/etc/hadoop/yarn-site.xml。
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml使用以下设置更改默认配置。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>完成后保存文件并退出编辑器。
现在运行以下命令启动 Yarn 守护进程。您应该会看到 ResourceManager 和 NodeManager 都在启动。
start-yarn.sh
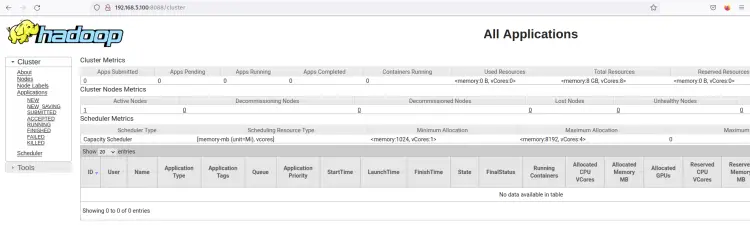
ResourceManager 应该在默认 pot 8088 上运行。回到您的 Web 浏览器并访问服务器 IP 地址,然后访问 ResourceManager 端口 8088(即:http://192.168.5.100:8088/)。
您应该会看到 hadoop ResourceManager 的 Web 界面。从这里,您可以监控 hadoop 集群内所有正在运行的进程。
单击“节点”菜单,您应该会看到 Hadoop 集群上当前正在运行的节点。
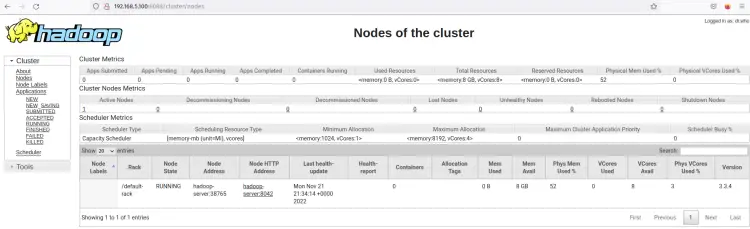
现在Hadoop集群以伪分布式模式运行。这意味着每个 Hadoop 进程都作为单个进程在单节点 Ubuntu 服务器 22.04 上运行,其中包括 NameNode、DataNode、MapReduce 和 Yarn。
结论
在本指南中,您在单机 Ubuntu 22.04 服务器上安装了 Apache Hadoop。您在启用伪分布式模式的情况下安装了 Hadoop,这意味着每个 Hadoop 组件都作为系统上的单个 Java 进程运行。在本指南中,您还学习了如何设置 Java、设置系统环境变量以及通过 SSH 公私密钥设置无密码 SSH 身份验证。
此类 Hadoop 部署,伪分布式模式,仅推荐用于测试。如果你想要一个可以处理中型或大型数据集的分布式系统,你可以以集群模式部署Hadoop,这需要更多的计算系统并为你的应用程序提供高可用性。