如何在 Ubuntu 14.04 上安装和使用 Memcache
介绍
随着网站的发展和流量的增加,显示压力最快的组件之一是后端数据库。如果您的数据库不是分布式的,也没有配置为处理高负载,它很容易被相对适度的流量增长所淹没。
处理此问题的一种方法是利用内存对象缓存系统,如 memcached。 Memcached 是一种缓存系统,它通过将通常从数据库检索的信息临时存储在内存中来工作。对内存中信息的下一个请求会非常快,而不会对后端数据库造成压力。
在本指南中,我们将讨论如何在 Ubuntu 14.04 服务器上安装和使用 memcached。
先决条件
在我们开始之前,您的服务器上应该有一个普通的非 root 用户,他可以访问 sudo 权限。如果您还没有创建这样的用户,您可以按照我们的 Ubuntu 14.04 初始设置指南中的步骤 1-4 来创建。
配置普通用户后,请继续阅读本指南。
安装 Memcached 和组件
开始之前,我们应该从 Ubuntu 的存储库中获取我们需要的所有组件。幸运的是,我们需要的一切都可用。
由于这是我们在此会话中使用 apt 进行的第一次操作,因此我们应该更新本地包索引。然后我们就可以安装我们的程序了。
我们将安装 memcached 以及 MySQL 数据库后端和 PHP 来处理交互。我们还安装了处理 memcached 交互的 PHP 扩展。您可以通过键入以下内容获得所需的一切:
sudo apt-get update
sudo apt-get install mysql-server php5-mysql php5 php5-memcached memcached
请注意,有 *两个PHP 内存缓存扩展可用。一个称为 php5-memcache,另一个称为 php5-memcached(请注意结尾的 \d第二个例子)。我们正在使用其中的第二个,因为它很稳定并且实现了更广泛的功能。
如果您尚未安装 MySQL,安装将提示您选择并确认管理员密码。
这应该安装和配置您需要的一切。
检查安装
信不信由你,memcached 已经完全安装并准备就绪。我们可以通过多种不同的方式对此进行测试。
第一种方式比较简单。我们可以只询问 PHP 是否知道我们的 memcached 扩展以及它是否已启用。我们可以通过创建无处不在的 PHP 信息页面来做到这一点。
这很容易通过在我们的文档根目录中创建一个名为 info.php 的文件来实现。在 Ubuntu 14.04 上的 Apache 中,我们默认的文档根目录是 /var/www/html。使用 root 权限打开这里的文件:
sudo nano /var/www/html/info.php
在这个文件中,输入这个。这基本上只是调用一个 PHP 函数,该函数收集有关我们服务器的信息并将其打印到 Web 友好的布局中。
<?php
phpinfo();
?>
现在,您可以访问服务器的域名或公共 IP 地址,然后访问 /info.php,您应该会看到一个信息页面。
<前>
如果您向下滚动或搜索 \memcached 部分标题,您应该会找到如下所示的内容:
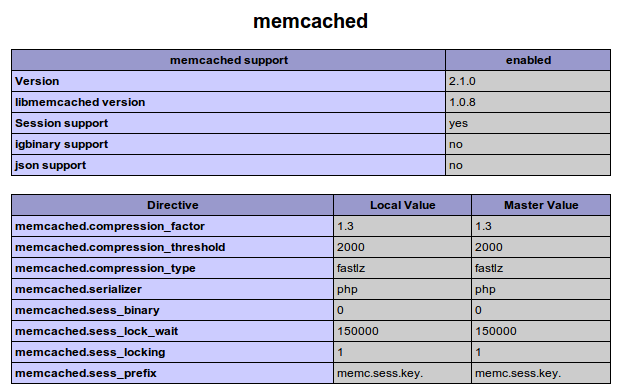
这意味着 memcached 扩展已启用并被 Web 服务器找到。
我们还可以通过键入以下内容来检查 memcached 服务是否正在运行:
ps aux | grep memcached
memcache 6584 0.0 0.0 327448 3004 ? Sl 14:07 0:00 /usr/bin/memcached -m 64 -p 11211 -u memcache -l 127.0.0.1
demouser 6636 0.0 0.0 11744 904 pts/0 S+ 14:29 0:00 grep --color=auto memcached
您可以通过键入以下内容来查询服务的统计信息:
echo "stats settings" | nc localhost 11211
如果您需要停止、启动或重新启动 memcached 服务,可以通过键入如下内容来完成:
<前>
测试Memcached是否可以缓存数据
现在我们已经验证了 memcached 正在运行并且我们的 PHP 扩展已经启用,我们可以尝试让它存储数据。
我们将通过创建另一个 PHP 脚本来完成此操作。这一次,它会更复杂。
在我们的文档根目录中打开一个名为 cache_test.php 的文件:
sudo nano /var/www/html/cache_test.php
在内部,首先创建 PHP 包装器标签:
<前>
在其中,我们将创建 PHP Memcached 对象的一个新实例并将其存储在一个变量中。我们将定义此 PHP 对象可以连接到我们服务器上运行的实际 memcached 服务的位置。默认情况下,Memcached 在 11211 端口上运行:
<前>
接下来,我们将告诉我们的 Memcached 实例从我们的缓存中查询一个键。这个键可以叫任何东西,因为我们还没有创建它。我们将使用 \blah。此请求的结果将存储到 $result 变量中:
<前>
$result=$mem->get(\blah);
接下来,我们只需要测试是否返回了任何东西。如果 memcached 找到一个名为 \blah 的键,我们希望它打印与该键关联的值。如果 memcached 无法找到匹配的键,我们应该打印出一条消息说明这一点。
然后我们应该为键设置一个值,以便下次我们请求该值时,memcached 会找到我们给它的值:
<前>
$result=$mem->get(\blah);
if ($result) {
至此,我们的脚本就完成了。如果我们在我们的网络浏览器中访问这个页面,我们可以看到它是如何工作的:
<前>
您最初应该看到一个如下所示的页面:
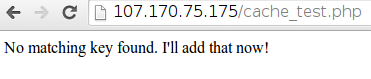
但是,如果我们刷新页面,我们应该会看到一条不同的消息:

如您所见,我们的 memcached 服务现在正在缓存我们的脚本设置的数据。
测试临时缓存数据库值
现在我们已经测试了在 memcached 中存储数据的能力,我们可以演示一个更现实的场景:临时缓存数据库查询的结果。
在 MySQL 中创建示例数据
为此,我们首先需要在数据库中存储一些信息。
通过键入以下命令以管理用户身份连接到您的 MySQL 实例。您必须输入在安装过程中设置的 MySQL root 密码:
mysql -u root -p
之后,你会得到一个 MySQL 提示符。
首先,我们要创建一个数据库进行测试。然后我们将选择数据库:
CREATE DATABASE mem_test;
USE mem_test;
让我们创建一个名为 test 的用户,其密码为 testing123,该用户可以访问我们创建的数据库:
GRANT ALL ON mem_test.* TO test@localhost IDENTIFIED BY 'testing123';
现在,我们将创建一个非常基本的表并向其中插入一条记录。该表将被称为 sample_data,它只有一个索引和一个字符串字段:
CREATE TABLE sample_data (id int, name varchar(30));
INSERT INTO sample_data VALUES (1, "some_data");
现在,我们已经创建了结构并插入了数据。我们可以退出MySQL:
exit
创建 PHP 脚本来缓存 MySQL 数据
现在我们在 MySQL 中有了数据,我们可以创建另一个 PHP 脚本,该脚本将以与生产 PHP 应用程序类似的方式运行。
它将在 memcached 中查找数据,如果找到数据则将其返回。如果没有找到数据,它会从数据库本身进行查询,然后将结果存储在 memcached 中以备将来查询。
首先,在我们的文档根目录中创建另一个 PHP 脚本。我们将调用此脚本 database_test.php:
sudo nano /var/www/html/database_test.php
以与我们上一个脚本类似的方式开始。我们将创建一个 PHP memcached 实例,然后告诉它运行在我们服务器上的 memcached 服务所在的位置,就像我们上次所做的那样:
<前>
接下来,与上一个脚本不同的是,我们必须定义 PHP 如何连接到我们的 MySQL 数据库。我们需要为我们创建的用户指定登录凭证,然后我们需要告诉它使用哪个数据库:
<前>
mysql_connect(\localhost, \test, \testing123) or die(mysql_error());
接下来,我们将不得不设计我们需要的查询来获取我们插入到表中的数据。我们会将其存储到 $query 变量中。
然后我们将创建一个 $querykey 变量来存储 memcached 将用来引用我们的信息的键。
我们通过使用字符串 \KEY” 创建此密钥,然后将查询的 md5(一种哈希方法)校验和附加到末尾。如果我们要在更大的数据集上使用此技术,这将确保每个密钥都是唯一的。它还确保匹配的查询将为后续请求生成相同的键。
<前>
mysql_connect(\localhost, \test, \testing123) 或 die(mysql_error());
$query=\SELECT ID FROM sample_data WHERE name=‘some_data’”;
接下来,我们将创建一个 $result 变量,就像我们上一个脚本一样。这将保留我们的 memcached 查询的结果,就像以前一样。我们向 memcached 询问我们生成的查询键,以查看它是否在其系统中具有由该键标识的记录。
<前>
mysql_connect(\localhost, \test, \testing123) 或 die(mysql_error());
$query=\SELECT name FROM sample_data WHERE id=1;
$result=$mem->get($querykey);
我们现在准备好执行实际的测试逻辑,以确定在 memcached 中找到结果时会发生什么。如果找到结果,我们想要打印我们提取的数据并告诉用户我们能够直接从 memcached 中检索它:
<前>
mysql_connect(\localhost, \test, \testing123) 或 die(mysql_error());
$query=\SELECT name FROM sample_data WHERE id=1;
$result=$mem->get($querykey);
if ($result) {
现在,让我们为备用场景添加逻辑。如果结果未 找到,我们希望使用我们精心设计的查询向 MySQL 请求数据。我们会将其存储到我们创建的 $result 变量中。这将采用数组的形式。
获得查询结果后,我们需要将该结果添加到 memcached,以便下次执行此操作时数据会在那里。我们可以通过向 memcached 提供我们想要用来引用数据的键(我们已经使用 $querykey 变量创建了它)、数据本身(存储在 $result 来自 MySQL 查询的变量),以及缓存数据的时间(以秒为单位)。
我们将缓存我们的内容 10 秒。在现实世界中,将内容缓存更长时间很可能是有益的。如果您的内容变化不大,可能会接近 10 分钟(600 秒)。对于测试,较小的值可以让我们更快地看到发生了什么,而无需重新启动我们的 memcached 服务。
之后,我们将打印出带有查询结果的类似消息,并告诉用户发生了什么。我们应该将整个块添加为我们之前的 if 的 else:
<前>
mysql_connect(\localhost, \test, \testing123) 或 die(mysql_error());
$query=\SELECT name FROM sample_data WHERE id=1;
$result=$mem->get($querykey);
如果($结果){
这是我们完成的脚本。它将尝试从 memcached 获取数据并返回它。如果失败,它将直接从 MySQL 查询并将结果缓存 10 秒。
测试脚本
现在我们已经编写了脚本,我们可以通过在 Web 浏览器中转到我们的文件位置来运行它:
<前>
第一次访问该页面时,我们应该看到如下所示的输出:
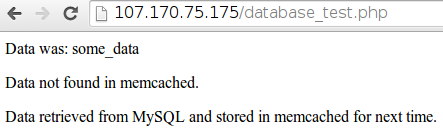
如果我们刷新它(在我们上次访问的 10 秒内),页面现在应该显示不同的消息:
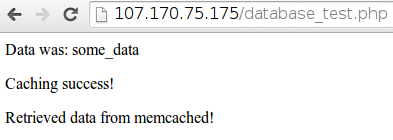
如果我们再等一下,缓存的内容将过期并再次从 memcached 中删除。我们可以在此时刷新以再次获取第一条消息,因为服务器必须返回数据库以获取适当的值。
结论
到目前为止,您应该对 memcached 的工作原理以及如何利用它来防止您的 Web 服务器重复访问数据库以获取相同的内容有一个很好的了解。
尽管我们在本指南中创建的 PHP 脚本只是示例,但它们应该能让您很好地了解系统的工作原理。它还应该让您很好地了解如何构建代码,以便您可以检查 memcached 并在必要时回退到数据库。