如何在 Ubuntu 22.04 上安装 TIG Stack(Telegraf、InfluxDB 和 Grafana)
本教程适用于这些操作系统版本
- Ubuntu 22.04(果酱水母)
- Ubuntu 18.04(仿生海狸)
在此页
- 先决条件
- 第 1 步 - 配置防火墙
- 第 2 步 - 安装 InfluxDB
- 第 3 步 - 创建 InfluxDB 数据库和用户凭证
- 第 4 步 - 安装 Telegraf
- 第 5 步 - 验证 Telegraf 统计数据是否存储在 InfluxDB 中
- 第 6 步 - 安装 Grafana
- 第 7 步 - 设置 Grafana 数据源
- 第 8 步 - 设置 Grafana 仪表板
- 第 9 步 - 配置警报和通知
- 条件
- 规则
- 无数据和错误处理
TIG(Telegraf、InfluxDB 和 Grafana)堆栈是开源工具平台的首字母缩写词,可简化系统指标的收集、存储、绘图和警报。您可以从一个地方监控和可视化内存、磁盘空间、登录用户、系统负载、交换使用、正常运行时间、运行进程等指标。栈中使用的工具如下:
- Telegraf - 是一种开源指标收集代理,用于收集和发送来自数据库、系统和物联网传感器的数据和事件。它支持各种输出插件,如 InfluxDB、Graphite、Kafka 等,它可以将收集的数据发送到这些插件。
- InfluxDB - 是一个用 Go 语言编写的开源时间序列数据库。它针对快速、高可用性存储进行了优化,适用于涉及大量时间戳数据的任何事物,包括指标、事件和实时分析。
- Grafana - 是一个开源数据可视化和监控套件。它支持各种输入插件,如 Graphite、ElasticSearch、InfluxDB 等。它提供了一个漂亮的仪表板和指标分析,允许您可视化和监控任何类型的系统指标和性能数据。
在本教程中,您将学习如何在单个 Ubuntu 22.04 服务器上安装和配置 TIG Stack。
先决条件
-
A server running Ubuntu 22.04.
-
A non-sudo user with root privileges.
-
The uncomplicated Firewall(UFW) is enabled and running.
-
Ensure that everything is updated.
$ sudo apt update && sudo apt upgrade
第 1 步 - 配置防火墙
在安装任何包之前,第一步是配置防火墙以打开 InfluxDB 和 Grafana 的端口。
检查防火墙的状态。
$ sudo ufw status您应该会看到如下内容。
Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6)为 InfluxDB 打开端口 8086,为 Grafana 服务器打开 3000。
$ sudo ufw allow 8086 $ sudo ufw allow 3000再次检查状态以确认。
$ sudo ufw status Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere 8086 ALLOW Anywhere 3000 ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6) 8086 (v6) ALLOW Anywhere (v6) 3000 (v6) ALLOW Anywhere (v6)第 2 步 - 安装 InfluxDB
我们将使用 InfluxDBs 官方存储库来安装它。
下载 InfluxDB GPG 密钥。
$ wget -q https://repos.influxdata.com/influxdb.key将 GPG 密钥导入服务器。
$ echo '23a1c8836f0afc5ed24e0486339d7cc8f6790b83886c4c96995b88a061c5bb5d influxdb.key' | sha256sum -c && cat influxdb.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/influxdb.gpg > /dev/null导入 InfluxDB 存储库。
$ echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdb.gpg] https://repos.influxdata.com/debian stable main' | sudo tee /etc/apt/sources.list.d/influxdata.list更新系统存储库列表。
$ sudo apt update您可以选择安装 InfluxDB 1.8.x 或 2.0.x。但是,最好使用最新版本。安装 InfluxDB。
$ sudo apt install influxdb2启动 InfluxDB 服务。
$ sudo systemctl start influxdb检查服务的状态。
$ sudo systemctl status influxdb ? influxdb.service - InfluxDB is an open-source, distributed, time series database Loaded: loaded (/lib/systemd/system/influxdb.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2022-09-13 00:00:27 UTC; 42s ago Docs: https://docs.influxdata.com/influxdb/ Process: 12514 ExecStart=/usr/lib/influxdb/scripts/influxd-systemd-start.sh (code=exited, status=0/SUCCESS) Main PID: 12515 (influxd) Tasks: 7 (limit: 1030) Memory: 48.5M CPU: 547ms CGroup: /system.slice/influxdb.service ??12515 /usr/bin/influxd ........第 3 步 - 创建 InfluxDB 数据库和用户凭证
要存储来自 Telegraf 的数据,您需要设置 Influx 数据库和用户。
InfluxDB 带有一个名为 influx 的命令行工具,用于与 InfluxDB 服务器进行交互。将
influx视为mysql命令行工具。运行以下命令来执行 Influx 的初始配置。
$ influx setup > Welcome to InfluxDB 2.0! ? Please type your primary username navjot ? Please type your password *************** ? Please type your password again *************** ? Please type your primary organization name howtoforge ? Please type your primary bucket name tigstack ? Please type your retention period in hours, or 0 for infinite 360 ? Setup with these parameters? Username: navjot Organization: howtoforge Bucket: tigstack Retention Period: 360h0m0s Yes User Organization Bucket navjot howtoforge tigstack您需要设置初始用户名、密码、组织名称、用于存储数据的主存储桶名称以及该数据的保留期(以小时为单位)。您的详细信息存储在
/home/username/.influxdbv2/configs文件中。您还可以通过在浏览器中启动 URL
http://来执行此设置。执行初始设置后,您可以使用上面创建的凭据登录到 URL。:8086/ 
您应该会看到以下仪表板。
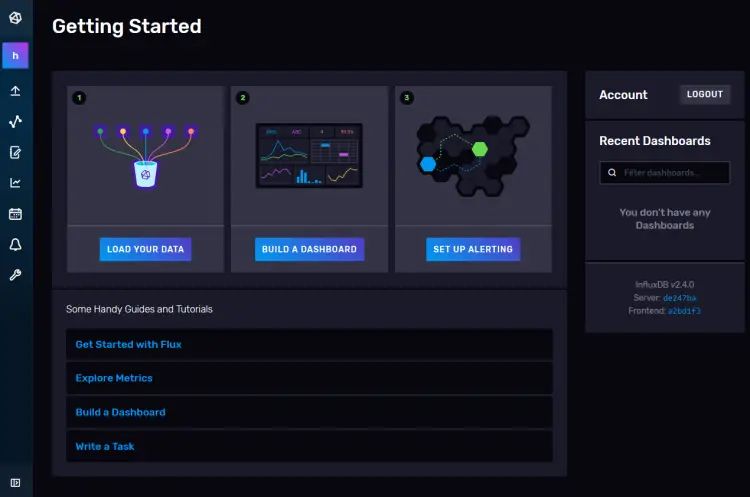
初始设置过程会创建一个默认令牌,该令牌具有对数据库中所有组织的完全读写访问权限。出于安全目的,您需要一个新令牌,它只会连接到我们要连接的组织和存储桶。
要创建新令牌,请单击左侧栏中的以下图标,然后单击 API 令牌链接以继续。
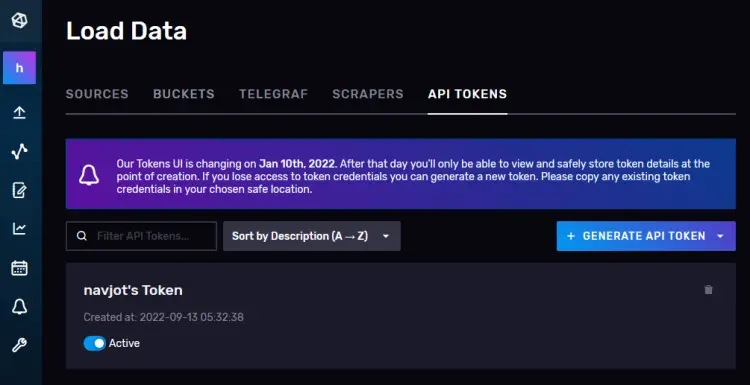
您将被带到 API 令牌页面。在这里,您将看到我们在初始配置时创建的默认令牌。
单击 Generate Token 按钮并选择 Read/Write Token 选项以启动新的覆盖弹出窗口。为令牌命名 (
telegraf) 并选择我们在读取和写入部分下创建的默认存储桶。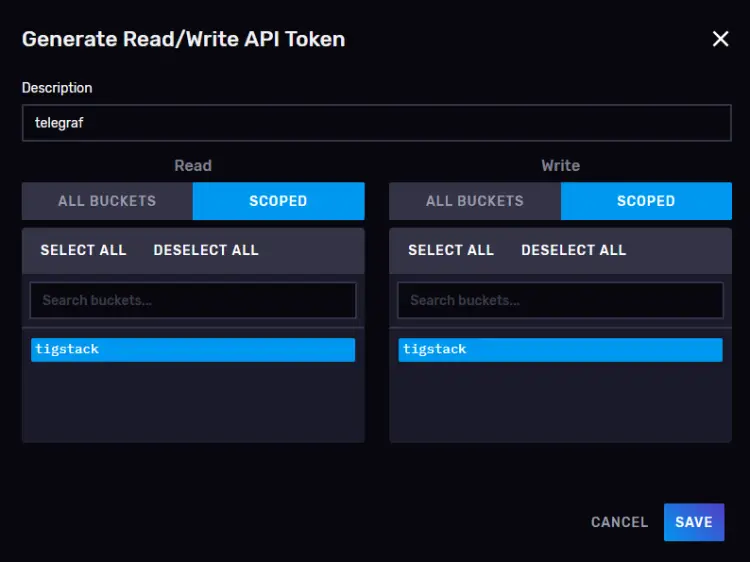
单击保存以完成创建令牌。单击新创建的令牌的名称以显示带有令牌值的弹出窗口。
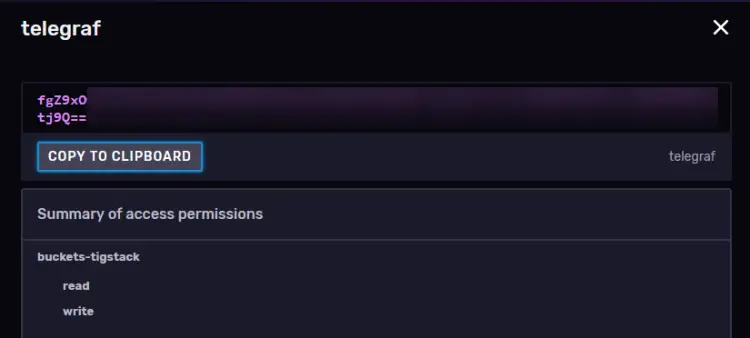
现在保存它,因为我们稍后会需要它。
这样就完成了 InfluxDB 的安装和配置。接下来,我们需要安装 Telegraf。
第 4 步 - 安装 Telegraf
Telegraf 和 InfluxDB 共享同一个存储库。这意味着您可以直接安装 Telegraf。
$ sudo apt install telegrafTelegrafs 服务在安装期间自动启用和启动。
Telegraf 是一个插件驱动的代理,有 4 种类型的插件:
<开始>
- 输入插件收集指标。
- 处理器插件转换、修饰和过滤指标。
- 聚合器插件创建和聚合指标。
- 输出插件定义发送指标的目的地,包括 InfluxDB。
Telegraf 将所有这些插件的配置存储在文件 /etc/telegraf/telegraf.conf 中。第一步是通过启用 influxdb_v2 输出插件将 Telegraf 连接到 InfluxDB。打开文件 /etc/telegraf/telegraf.conf 进行编辑。
$ sudo nano /etc/telegraf/telegraf.conf
找到行 [[outputs.influxdb_v2]] 并通过删除它前面的 # 取消注释。按照以下方式编辑掉它下面的代码。
# # Configuration for sending metrics to InfluxDB 2.0
[[outputs.influxdb_v2]]
# ## The URLs of the InfluxDB cluster nodes.
# ##
# ## Multiple URLs can be specified for a single cluster, only ONE of the
# ## urls will be written to each interval.
# ## ex: urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"]
urls = ["http://127.0.0.1:8086"]
#
# ## Token for authentication.
token = "$INFLUX_TOKEN"
#
# ## Organization is the name of the organization you wish to write to.
organization = "howtoforge"
#
# ## Destination bucket to write into.
bucket = "tigstack"
粘贴之前保存的 InfluxDB 令牌值,以代替上面代码中的 $INFLUX_TOKEN 变量。
搜索 INPUT PLUGINS 行,您将看到默认启用的以下输入插件。
# Read metrics about cpu usage
[[inputs.cpu]]
## Whether to report per-cpu stats or not
percpu = true
## Whether to report total system cpu stats or not
totalcpu = true
## If true, collect raw CPU time metrics
collect_cpu_time = false
## If true, compute and report the sum of all non-idle CPU states
report_active = false
## If true and the info is available then add core_id and physical_id tags
core_tags = false
# Read metrics about disk usage by mount point
[[inputs.disk]]
## By default stats will be gathered for all mount points.
## Set mount_points will restrict the stats to only the specified mount points.
# mount_points = ["/"]
## Ignore mount points by filesystem type.
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
## Ignore mount points by mount options.
## The 'mount' command reports options of all mounts in parathesis.
## Bind mounts can be ignored with the special 'bind' option.
# ignore_mount_opts = []
# Read metrics about disk IO by device
[[inputs.diskio]]
....
....
# Get kernel statistics from /proc/stat
[[inputs.kernel]]
# no configuration
# Read metrics about memory usage
[[inputs.mem]]
# no configuration
# Get the number of processes and group them by status
[[inputs.processes]]
# no configuration
# Read metrics about swap memory usage
[[inputs.swap]]
# no configuration
# Read metrics about system load & uptime
[[inputs.system]]
# no configuration
您可以根据需要配置其他输入插件,包括 Apache Server、Docker 容器、Elasticsearch、iptables 防火墙、Kubernetes、Memcached、MongoDB、MySQL、Nginx、PHP-fpm、Postfix、RabbitMQ、Redis、Varnish、Wireguard、PostgreSQL 等。
完成后,按 Ctrl + X 并在出现提示时输入 Y 来保存文件。
完成应用更改后重新启动 Telegraf 服务。
$ sudo systemctl restart telegraf
第 5 步 - 验证 Telegraf 统计数据是否存储在 InfluxDB 中
在继续之前,您需要验证 Telegraf 统计数据是否已正确收集并输入到 InfluxDB 中。在浏览器中打开 InfluxDB UI,单击左侧栏中的第三个图标,然后选择 Buckets 菜单。
单击 tigstack,您应该会看到以下页面。
单击存储桶名称,然后单击 _measurement 过滤器中的值之一,并在其他值出现时继续单击它们。完成后,单击提交按钮。您应该在顶部看到一个图表。您可能需要等待一段时间才能显示数据。
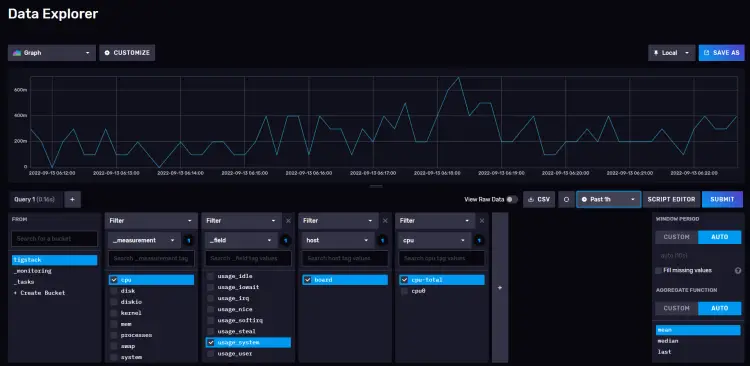
这应该确认数据正在正确传递。
第 6 步 - 安装 Grafana
我们将使用官方 Grafana 存储库来安装它。导入 Grafana GPG 密钥。
$ sudo wget -q -O /usr/share/keyrings/grafana.key https://packages.grafana.com/gpg.key
将存储库添加到您的系统。
$ echo "deb [signed-by=/usr/share/keyrings/grafana.key] https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
更新系统存储库列表。
$ sudo apt update
安装格拉法纳。
$ sudo apt install grafana
启动并启用 Grafana 服务。
$ sudo systemctl enable grafana-server --now
检查服务状态。
$ sudo systemctl status grafana-server
? grafana-server.service - Grafana instance
Loaded: loaded (/lib/systemd/system/grafana-server.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2022-09-13 01:04:47 UTC; 2s ago
Docs: http://docs.grafana.org
Main PID: 13674 (grafana-server)
Tasks: 7 (limit: 1030)
Memory: 104.6M
CPU: 1.050s
CGroup: /system.slice/grafana-server.service
??13674 /usr/sbin/grafana-server --config=/etc/grafana/grafana.ini --pidfile=/run/grafana/grafana-server.pid --packaging=deb cfg:default.paths.logs=/var/log/grafana
.......
第 7 步 - 设置 Grafana 数据源
在您的浏览器中启动 URL http://,您应该会看到以下 Grafana 登录页面。
使用默认用户名 admin 和密码 admin 登录。接下来,您需要设置一个新的默认密码。
您将看到以下 Grafana 主页。单击添加您的第一个数据源按钮。
单击 InfluxDB 按钮。
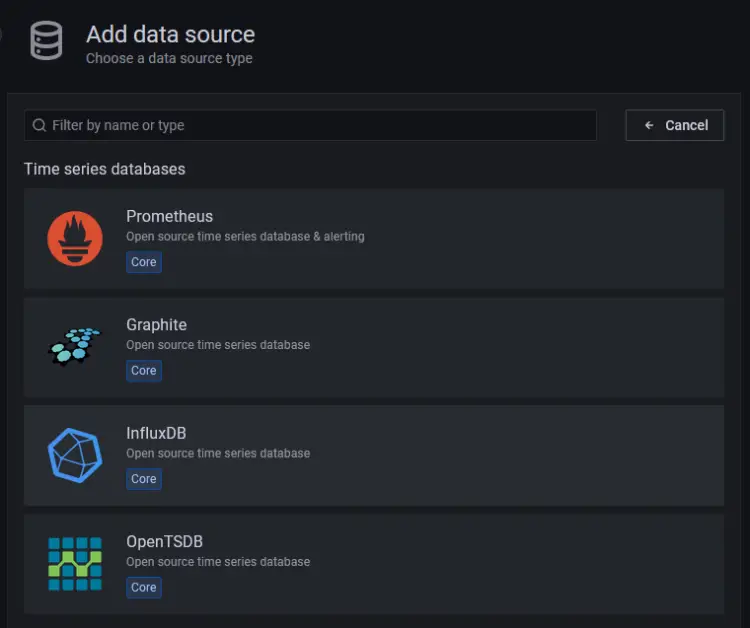
在下一页上,从下拉菜单中选择 Flux 作为查询语言。您可以使用 InfluxQL 作为查询语言,但配置起来比较复杂,因为它默认仅支持 InfluxDB v1.x。 Flux 支持 InfluxDB v2.x,并且更易于设置和配置。
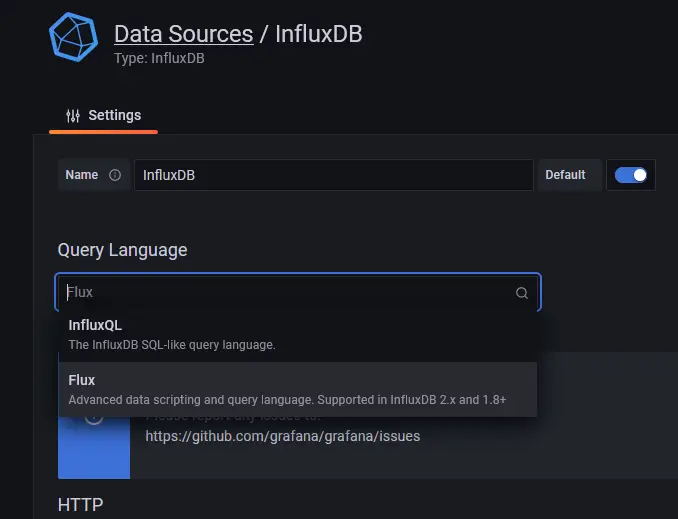
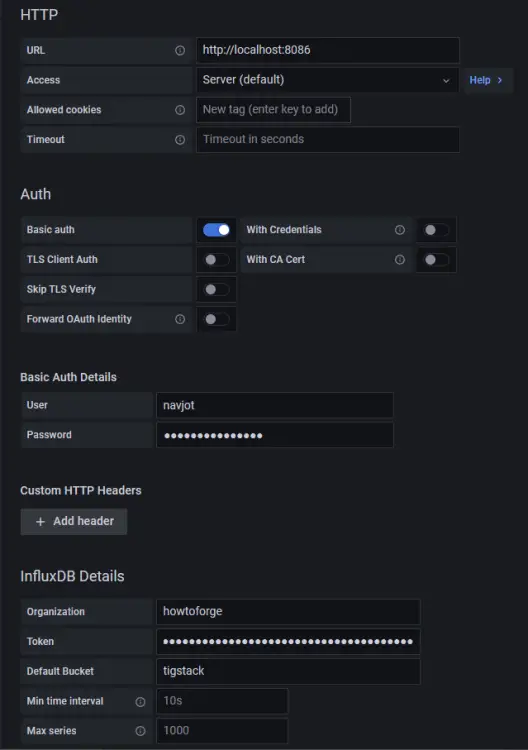
输入以下值。
网址:http://localhost:8086
访问:服务器
基本授权详细信息
用户:navjot
密码:
InfluxDB 详细信息
组织:howtoforge
令牌:
默认桶:tigstack
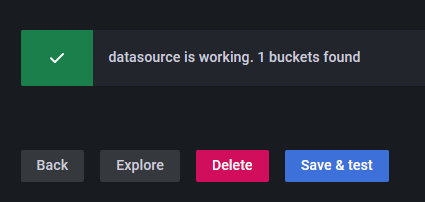
单击“保存并测试”按钮,您应该会看到一条确认消息,确认设置已成功。
第 8 步 - 设置 Grafana 仪表板
下一步是设置 Grafana 仪表板。单击带有四个方块的符号并选择仪表板以打开仪表板创建屏幕。
在下一页上,单击“添加新面板”按钮以启动以下屏幕。
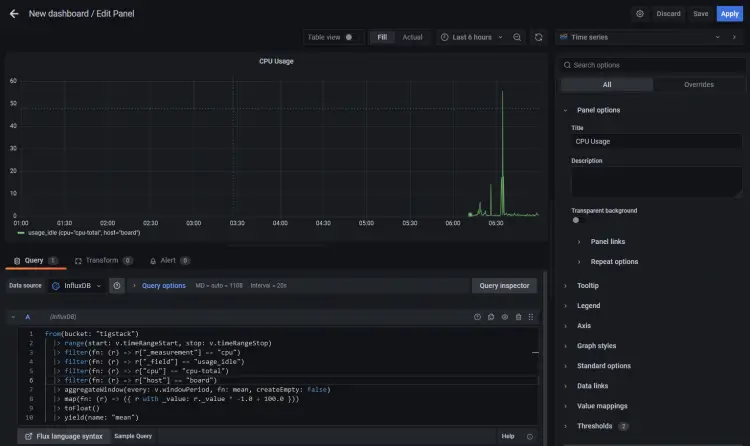
将以下代码粘贴到查询编辑器中。这个
from(bucket: "NAMEOFYOUBUCKET")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_idle")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({ r with _value: r._value * -1.0 + 100.0 }))
|> toFloat()
|> yield(name: "mean")
使用我们上面使用的存储桶名称。以及您可以从文件 /etc/hostname 中检索到的主机名。
上面的代码将计算 CPU 使用率并为其生成图表。给面板一个标题。
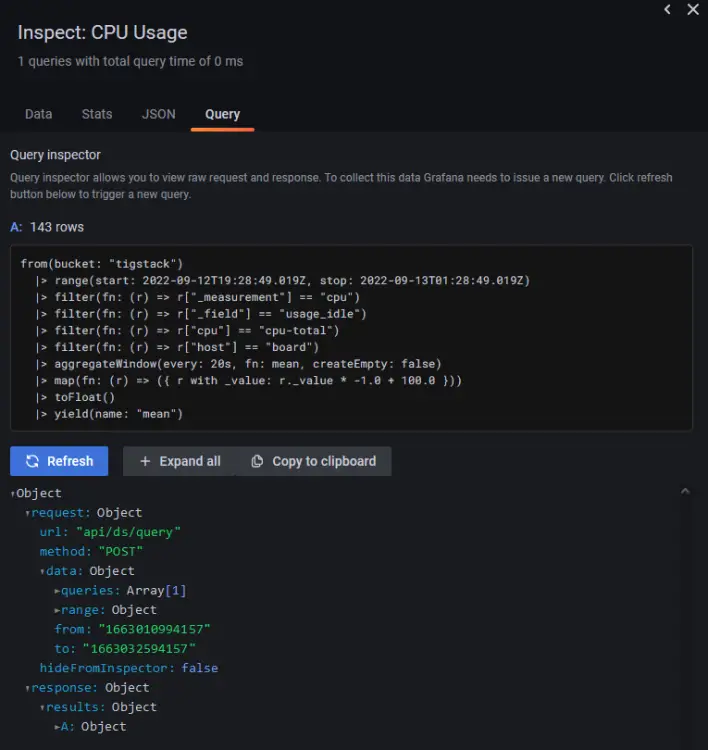
单击 Query inspector 按钮,然后单击 Refresh 按钮以验证您的查询是否成功运行。单击十字图标关闭检查器。
您还可以使用“轴”部分右侧的“标签”字段来命名轴。
单击“应用”按钮保存面板。
完成后单击保存仪表板按钮。
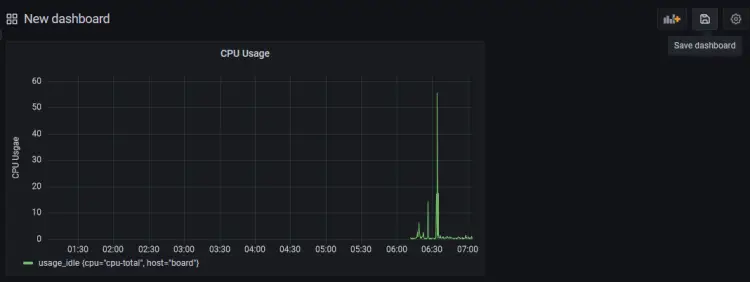
为仪表板命名并单击保存以完成。
它将打开仪表板,然后单击“添加面板”按钮以创建另一个面板。
通过为 RAM 使用创建另一个面板来重复该过程。
from(bucket: "NAMEOFYOUBUCKET")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "mem")
|> filter(fn: (r) => r["_field"] == "used_percent")
|> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")
并使用以下代码显示硬盘使用情况。
from(bucket: "NAMEOFYOURBUCKET")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "disk")
|> filter(fn: (r) => r["_field"] == "used")
|> filter(fn: (r) => r["path"] == "/")
|> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({ r with _value: r._value / 1000000.0 }))
|> toFloat()
|> yield(name: "mean")
您可以创建无限数量的面板。
以上代码基于 Flux Scripting 语言。幸运的是,您不需要学习编写查询的语言。您可以从 InfluxDB URL 生成查询。即使学习语言可以在优化查询方面受益。
您需要返回 InfluxDB 仪表板并打开 Explore 页面以获取查询。
单击存储桶名称,然后单击 _measurement 过滤器中的值之一,并在其他值出现时继续单击它们。完成后,单击脚本编辑器按钮,您应该会看到以下页面。该图也应更新。
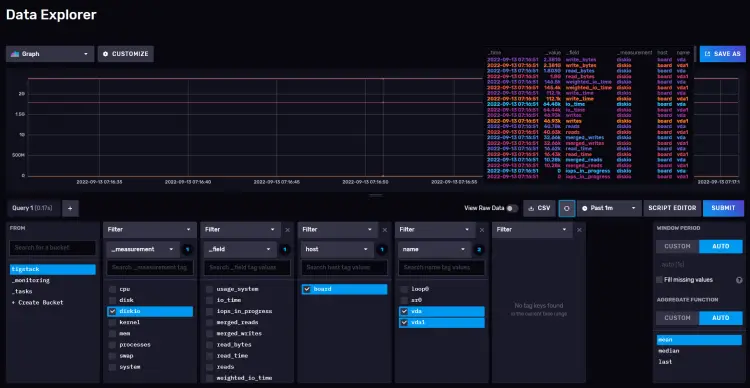
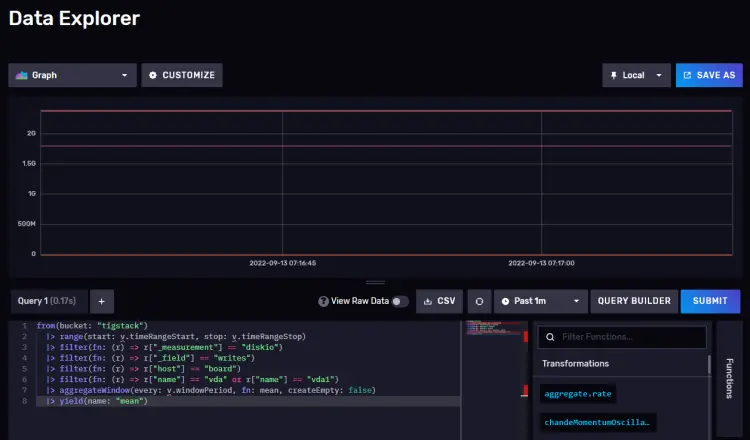
复制显示的查询,您现在可以在 Grafana 仪表板中使用它来构建图表。
第 9 步 - 配置警报和通知
设置监视器的主要用途是在值超过特定阈值时及时获得警报。
第一步是设置您想要接收警报的目的地。您可以通过电子邮件、Slack、Kafka、Google Hangouts Chat、Microsoft Teams、Telegram 等接收通知。
我们将为我们的教程启用电子邮件通知。要设置电子邮件通知,我们需要先配置 SMTP 服务。打开/etc/grafana/grafana.ini文件配置SMTP。
$ sudo nano /etc/grafana/grafana.ini
在其中找到以下行 [smtp]。取消注释以下行并输入自定义 SMTP 服务器的值。
[smtp]
enabled = true
host = email-smtp.us-west-2.amazonaws.com:587
user = YOURUSERNAME
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password = YOURUSERPASSWORD
;cert_file =
;key_file =
;skip_verify = false
from_address =
from_name = HowtoForge Grafana
# EHLO identity in SMTP dialog (defaults to instance_name)
;ehlo_identity = dashboard.example.com
# SMTP startTLS policy (defaults to 'OpportunisticStartTLS')
;startTLS_policy = NoStartTLS
通过按 Ctrl + X 并在出现提示时输入 Y 来保存文件。
重新启动 Grafana 服务器以应用设置。
$ sudo systemctl restart grafana-server
打开 Grafana 页面并单击警报图标,然后单击联系点。
Grafana 自动创建并设置一个默认的电子邮件联系点,需要使用正确的电子邮件地址进行配置。单击 grafana-default-email 联系点上的编辑按钮。
输入详细信息以设置电子邮件通知渠道。
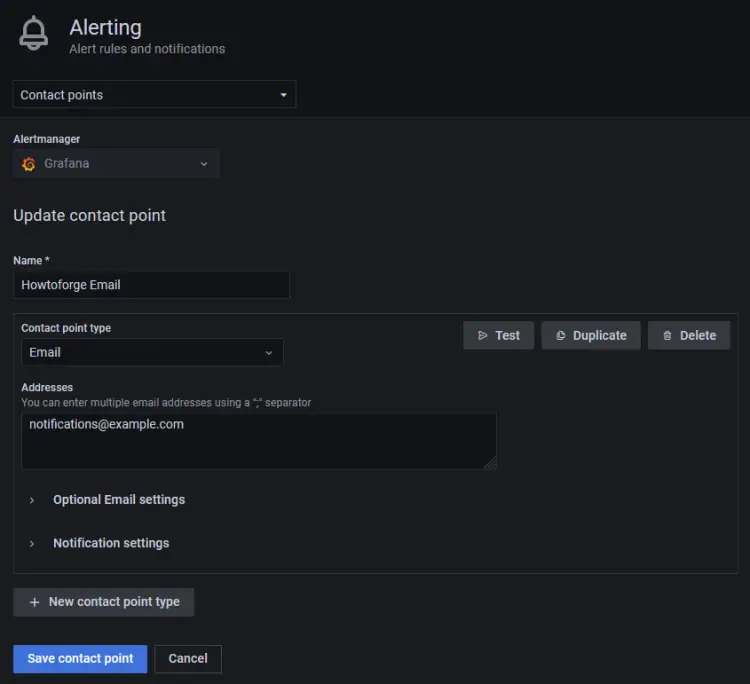
如果要发送其他消息,请单击可选电子邮件设置链接并输入消息。
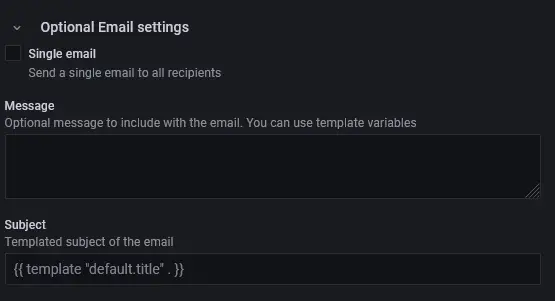
单击测试以查看电子邮件设置是否正常工作。完成后单击保存。
现在我们已经设置了通知渠道,我们需要设置何时收到这些电子邮件的警报。要设置警报,您需要返回仪表板面板。
单击仪表板 >> 浏览以打开仪表板页面。
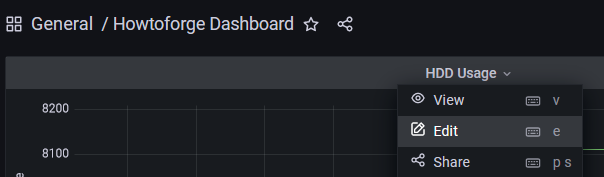
单击我们刚刚创建的仪表板,您将获得包含不同面板的主页。要编辑面板,请单击面板的名称,然后会弹出一个下拉菜单。单击“编辑”链接继续。
单击“警报面板”,然后单击“从此面板创建警报规则”按钮以设置新警报。
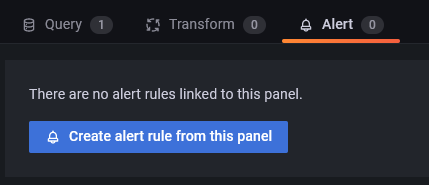
您现在可以配置 Grafana 发送警报的条件。
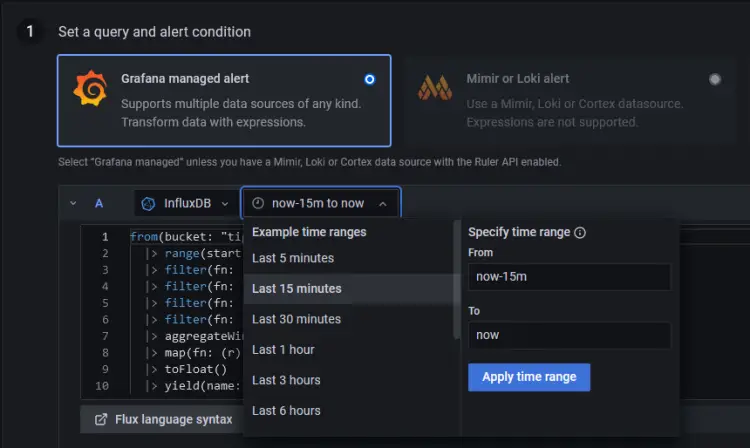
默认情况下,选择的警报类型是 Grafana 管理的警报。单击下拉菜单将时间范围更改为最近 15 分钟,这意味着它将检查从 15 分钟前到现在。
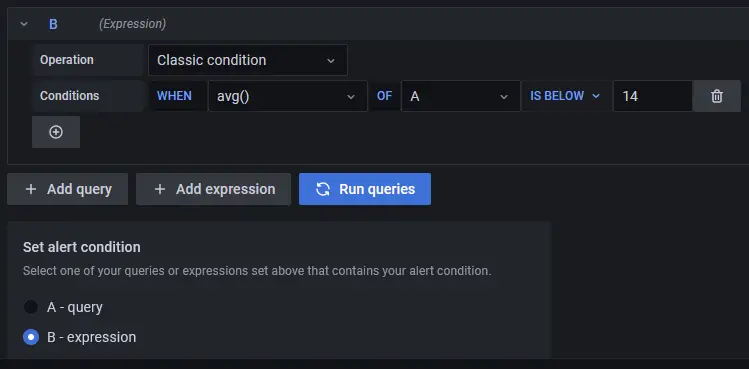
情况
Grafana 处理以下格式的查询以确定何时启动警报。
avg() OF query(A) IS BELOW 14
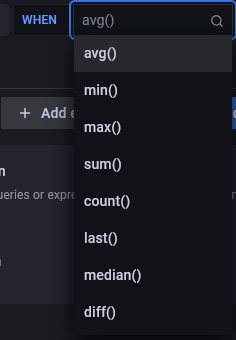
- avg() 控制每个系列的值应如何减少到与阈值相当的值。您可以单击函数名称来选择不同的函数,例如 avg()、min()、max()、sum()、count() 等。
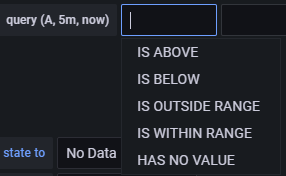
您可以通过单击第一个条件下方的 + 按钮在其下方添加第二个条件。目前,您只能在多个条件之间使用 AND 和 OR 运算符。
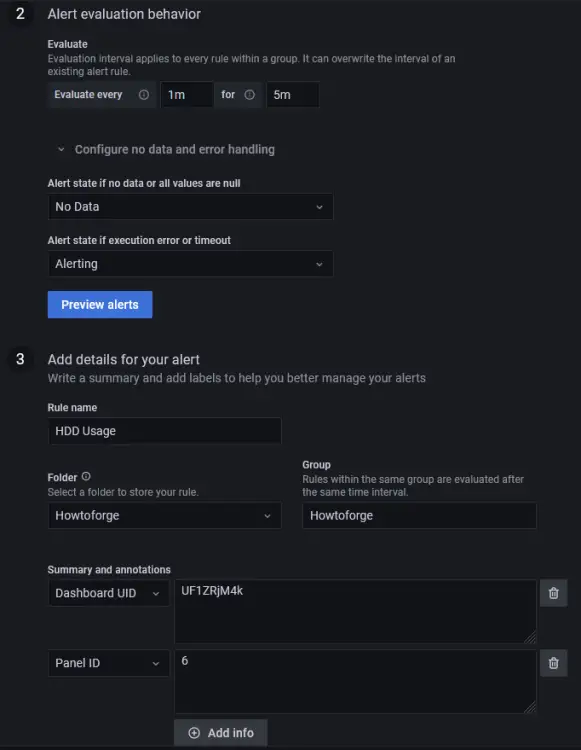
规则
- 名称 - 输入警报的描述性名称
- 文件夹 - 创建或选择一个预先存在的文件夹来存储您的通知规则。
- 组 - 输入警报组的名称。在同一时间间隔后评估单个组中的警报。
- Evaluate every - 指定 Grafana 评估警报的频率。它也称为评估区间。您可以在这里设置任何您想要的值。
无数据和错误处理
您可以使用以下条件配置 Grafana 如何处理不返回数据或仅返回空值的查询:
<开始>
NoData Alerting 您可以告诉 Grafana 如何处理执行或超时错误。
<开始>
Alerting 完成后,单击按钮预览警报以查看是否一切正常。单击右上角的保存并退出按钮以完成添加警报。您现在应该开始在您的电子邮件中收到警报。
结论
关于在基于 Ubuntu 22.04 的服务器上安装和配置 TIG Stack 的教程到此结束。如果您有任何问题,请在下面的评论中发表。