Elasticsearch 和 Kibana:在 Ubuntu 16.04 上的安装和基本使用
在此页
- 1 安装 Java
- 2 安装 Elasticsearch
- 3 配置和运行 Elasticsearch
- 4 安装 Kibana
- 5 配置和运行 Kibana
- 6 基本用法
- 6.1 创建索引
- 6.2 插入一些数据到索引
- 6.3 从索引中获取数据
Elasticsearch 是一个用 Java 编写的强大的生产就绪搜索引擎。它可以用作网络的独立搜索引擎或电子商务网络应用程序的搜索引擎。
eBay、Facebook 和 Netflix 是使用该平台的一些公司。 Elasticsearch 之所以如此受欢迎,是因为它不仅仅是一个搜索引擎。它还是一个强大的分析引擎和一个日志管理和检索系统。关于它的最好的部分是它是开源的并且可以免费使用。 Kibana是elastic提供的可视化工具。
在本教程中,我们将完成 Elasticsearch 的安装步骤,然后安装 Kibana。然后我们将使用 Kibana 来存储和检索数据。
1 安装Java
由于 Elasticsearch 是用 Java 编写的,因此必须先安装它。使用以下命令安装 JRE 和 JDK 的开源版本:
sudo apt-get install default-jre
sudo apt-get install default-jdk这两个命令将在您的系统上安装最新的 open-jre 和 open-jdk。我将在这里使用 JAVA 8。下图显示,当您没有安装 java 并运行上述命令时,您将获得的输出。
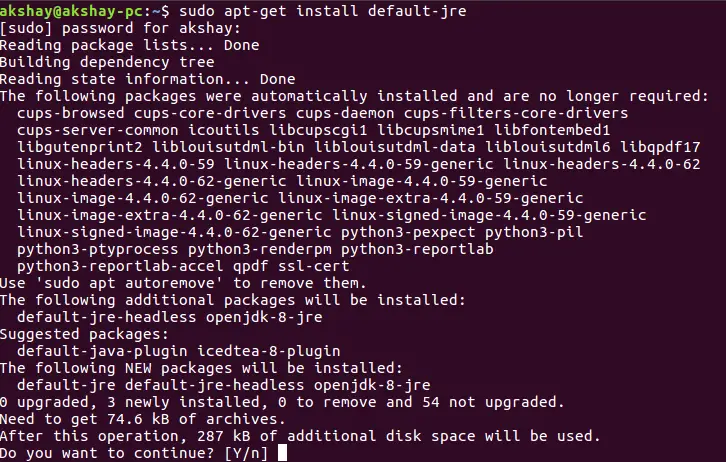
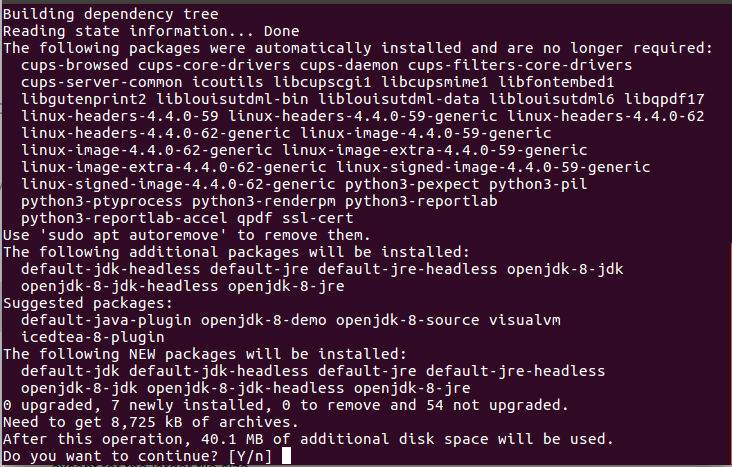
2 安装弹性搜索
Elasticsearch 5 最近发布了。与之前的 2.x 版本相比,它有一些巨大的变化。在撰写本文时,版本 5.2.2 是最新版本,我们将安装它。所以请按照以下步骤进行安装。
mkdir elasticsearch; cd elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.deb有了这个,.deb 文件应该开始下载。它看起来类似于下图:
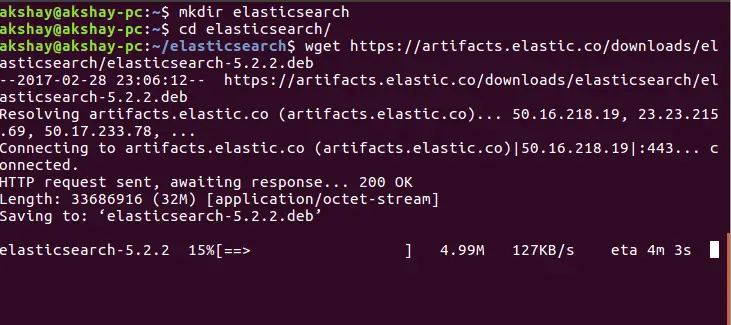
下载成功完成后,我们可以通过运行以下命令来安装它。安装成功的输出如下。
sudo dpkg -i elasticsearch-5.2.2.deb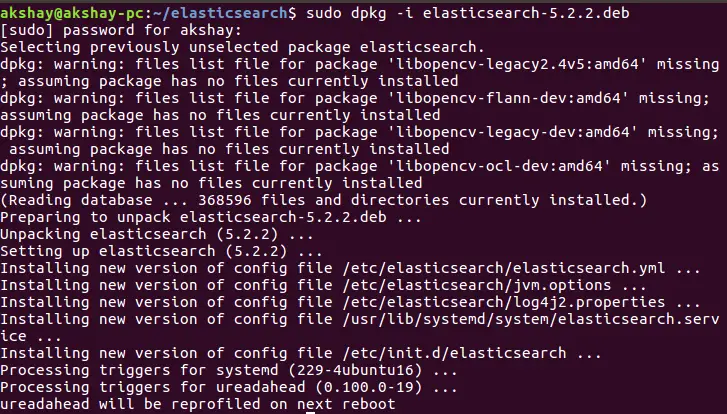
3 配置并运行 Elasticsearch
Elasticsearch 作为后台进程运行。但在我们启动它之前,我们必须编辑配置文件以将当前系统添加为运行引擎的主机。使用以下命令打开配置文件:
sudo gedit /etc/elasticsearch/elasticsearch.yml编辑器打开后,您必须取消注释该行:
#network.host: 192.168.0.1然后将 IP 更改为 localhost,如下图所示:

现在,我们已准备好运行该过程。使用以下命令:
sudo systemctl daemon-reloadsudo systemctl enable elasticsearchsudo systemctl restart elasticsearch这三个命令将 Elasticsearch 进程添加到系统守护进程,以便它会在系统启动时自动启动,然后重新启动进程本身。要测试系统是否已启动并正在运行,请使用以下命令。输出应类似于下图所示。
curl -XGET "http://localhost:9200"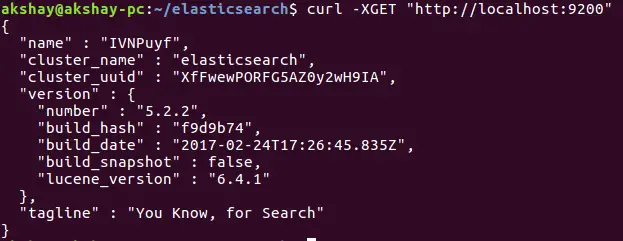
4 安装基巴纳
使用以下命令下载并安装 deb 文件:
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.2.2-amd64.debsudo dpkg -i kibana-5.2.2-amd64.deb在运行第二个命令时,如果它要求您修改现有的 Kibana 配置文件,您可以按 enter 键以保持默认值并完成比赛。安装后,它看起来类似于下图。
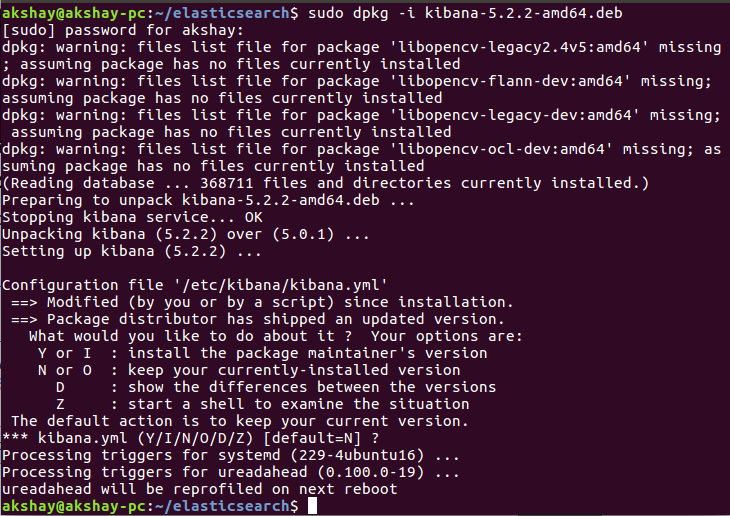
5 配置并运行 Kibana
在 Kibana 配置文件中,取消注释以下行:
server.port:
server.host:
server.name:
elasticsearch.name:
kibana.index:使用以下命令打开配置文件。进行更改后的文件应如下图所示:
sudo gedit /etc/kibana/kibana.yml\server.name\ 可以是任何东西,所以请随意更改它。完成这些更改后,保存并关闭文件。最后要做的是将 Kibana 进程添加到系统进程列表中,以便它在每次系统启动时自动启动。运行以下命令:
sudo systemctl daemon-reloadsudo systemctl enable kibanasudo systemctl start kibana运行这些命令后,您可以打开网络浏览器并使用以下 URL 测试它是否已正确安装。下图显示了它的外观:
http://localhost:5601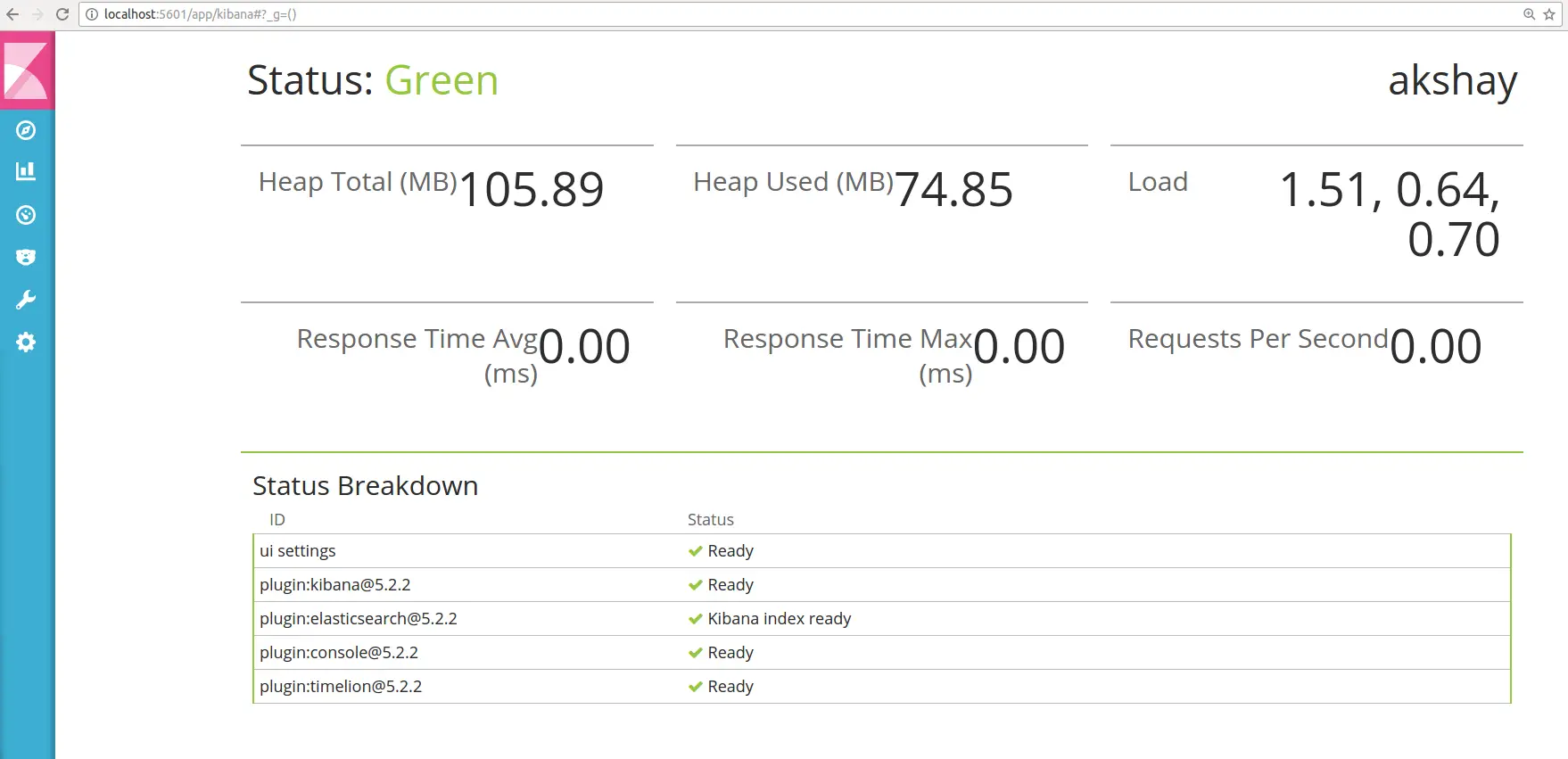
就是这样。您现在已经成功安装了 Kibana 和 Elasticsearch。
6 基本用法
我们可以使用 Kibana 提供的“开发工具”实用程序与 Elasticsearch 对话。它提供了一个干净简单的界面来将命令作为 JSON 对象执行。我们将通过 REST 接口与核心引擎交互。

http://localhost:5601/app/kibana#/dev_tools/加载后,您将看到 UI 的“欢迎使用控制台”介绍。您可以阅读该介绍或只需单击该介绍底部的“开始工作”按钮。单击该按钮后,用户界面将如下图所示:
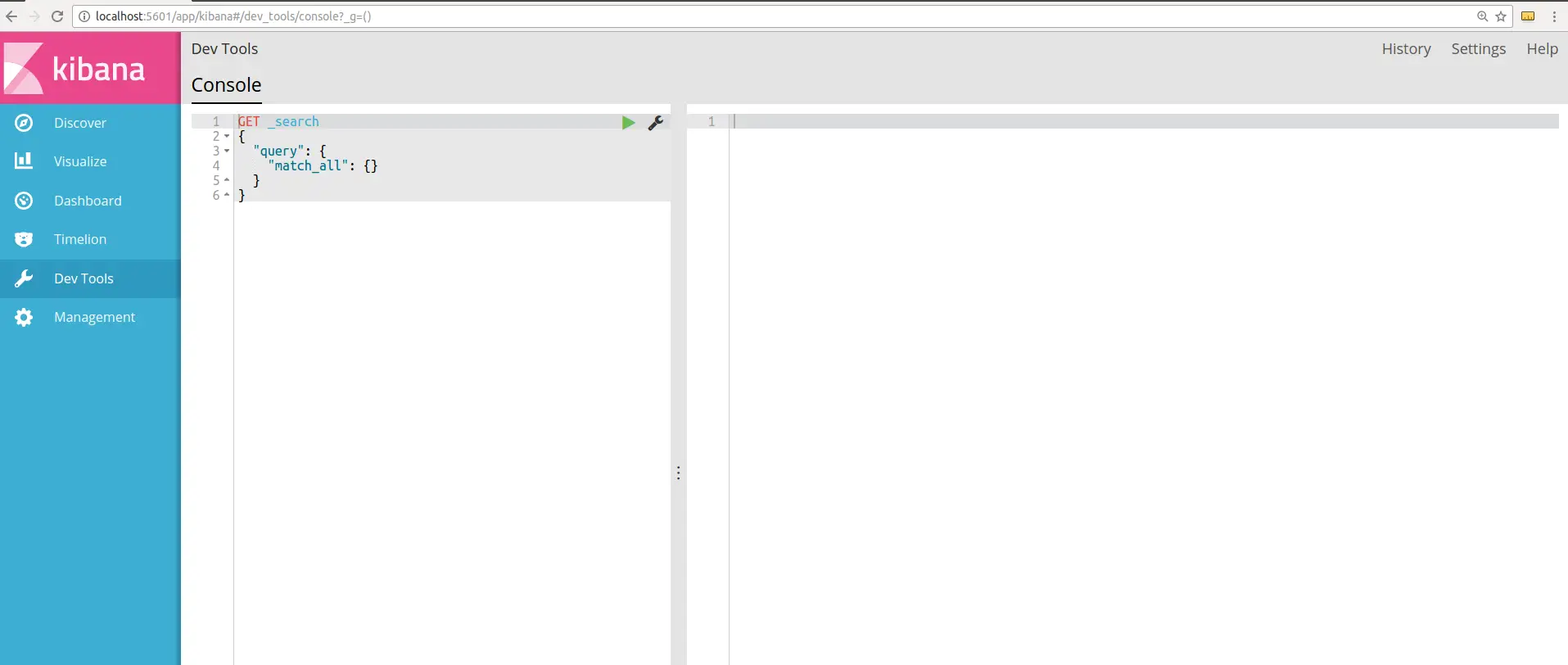
在左侧,我们将键入命令,在右侧面板,我们将获得输出。让我们尝试向搜索引擎发送和存储一些数据。
6.1 创建索引
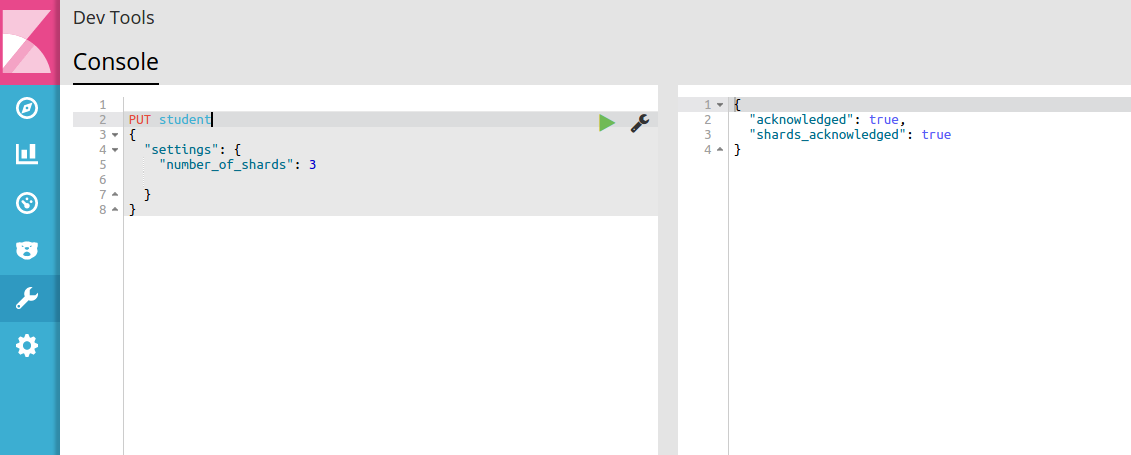
数据存储在索引中。要创建索引,我们使用 PUT 命令。请求 JSON 将包含索引的名称和我们可以提供的一些可选设置。以下命令是创建名为“student”的索引的示例。
PUT student
{
"settings": {
"number_of_shards": 3
}
}您可以在“开发工具”中输入它,然后按旁边的绿色播放按钮运行它。输出将类似于下图:
6.2 插入一些数据进行索引
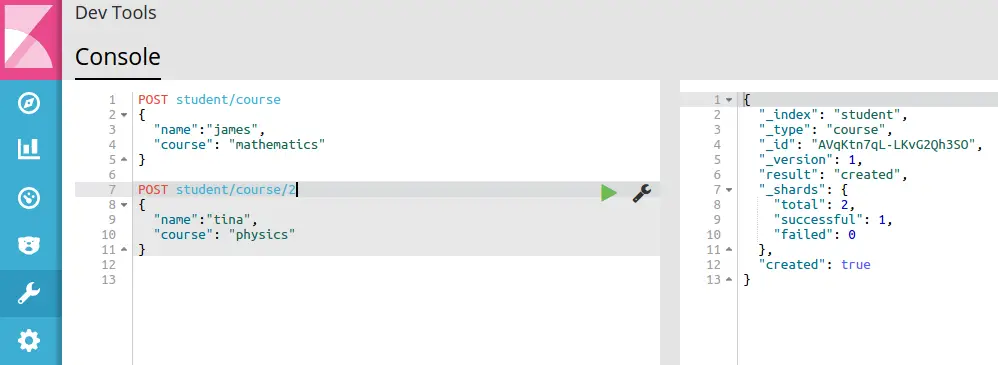
我们将使用 POST 调用将数据插入索引。要插入的数据采用 JSON 格式,因此让我们继续将学生添加到索引中。命令是:
POST student/course
{
"name":"james",
"course": "mathematics"
}在上面的命令中,\course\ 表示被索引的数据类型。从响应中,您可以看到,该条目也有一个唯一的 ID。在下面的命令中,您可以看到在“course”之后还有另一个参数,这是您可以指定该学生条目的 id 的方式。这样,elasticsearch 就不会费心创建 ID,而是将其用作此记录的 ID。
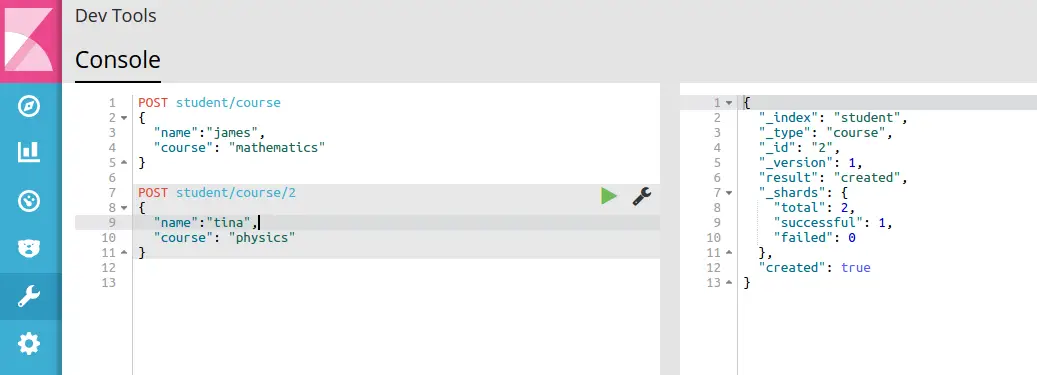
POST student/course/2
{
"name":"tina",
"course": "physics"
}以下图像显示了运行这两个命令时搜索引擎的响应:
6.3 从索引中获取数据
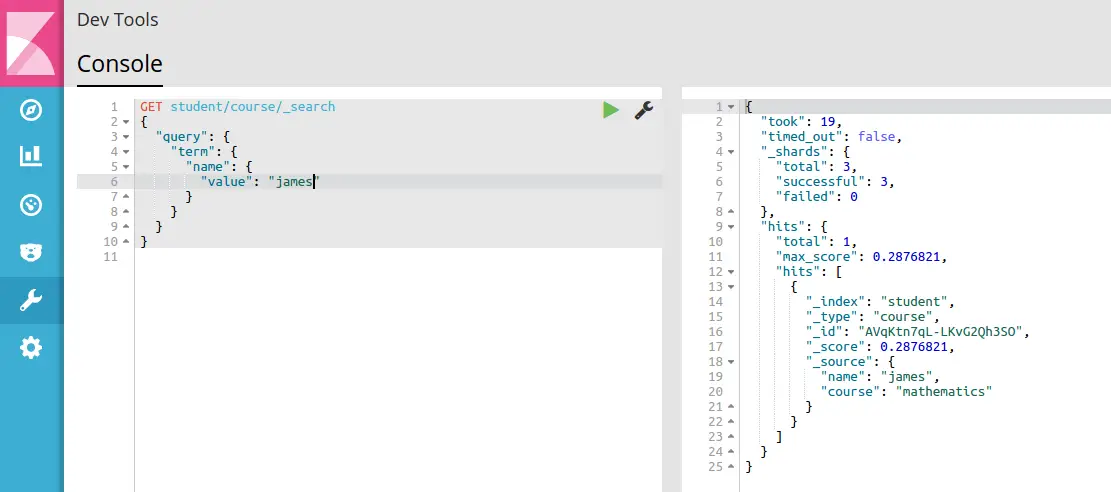
您还可以从存储的记录或条目中的各个字段中获取数据。我们在上一步中保存的每个条目在 Elasticsearch 中称为文档。我们将使用 GET 调用从索引中获取文档。以下是如何使用“名称”字段获取一个文档:
GET student/course/_search
{
"query": {
"term": {
"name": {
"value": "james"
}
}
}
}此命令在 \student\ 索引中搜索类型为 \course\ 的文档,并尝试匹配字段名称为 \name\ 且值为 \James\ 的术语。由于索引中有一个名为 James 的学生,我们得到如下图所示的响应:
这些只是基础知识,Elasticsearch 可以做很多事情,需要进行大量探索才能掌握这个框架并充分利用它。