如何从 Linux 命令行管理 Samba4 AD 基础设施 - 第 2 部分
本教程将介绍管理 Samba4 AD 域控制器基础设施所需使用的一些基本日常命令,例如添加、删除、禁用或列出用户和组。
我们还将了解如何管理域安全策略以及如何将 AD 用户绑定到本地 PAM 身份验证,以便 AD 用户能够在 Linux 域控制器上执行本地登录。
要求
- 在 Ubuntu 16.04 上使用 Samba4 创建 AD 基础设施 – 第 1 部分
- 通过 RSAT 从 Windows10 管理 Samba4 Active Directory 基础设施 – 第 3 部分
- 从 Windows 管理 Samba4 AD 域控制器 DNS 和组策略 – 第 4 部分
步骤 1:从命令行管理 Samba AD DC
1. Samba AD DC 可以通过 samba-tool 命令行实用程序进行管理,该实用程序提供了一个用于管理域的出色界面。
借助 samba-tool 界面,您可以直接管理域用户和组、域组策略、域站点、DNS 服务、域复制和其他关键域功能。
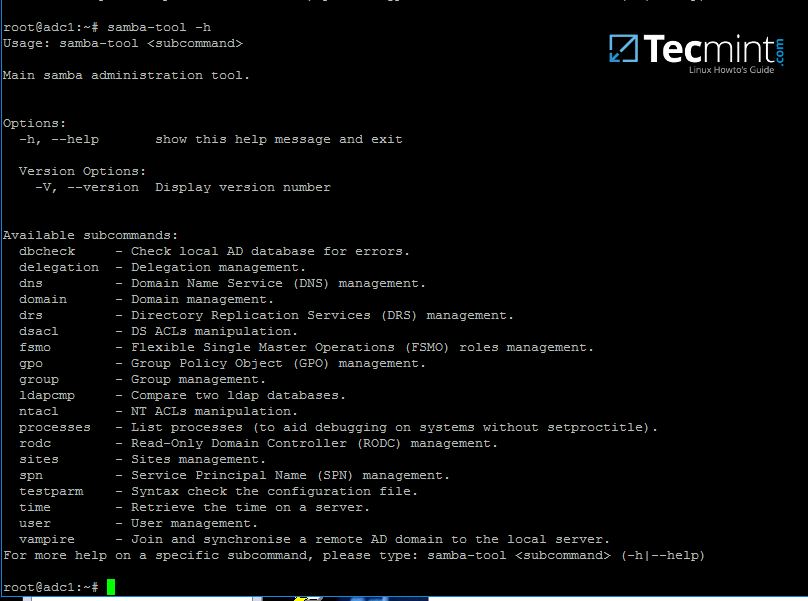
要查看 samba-tool 的全部功能,只需使用 root 权限键入命令,无需任何选项或参数。
samba-tool -h
2. 现在,让我们开始使用 samba-tool 实用程序来管理 Samba4 Active Directory 并管理我们的用户。
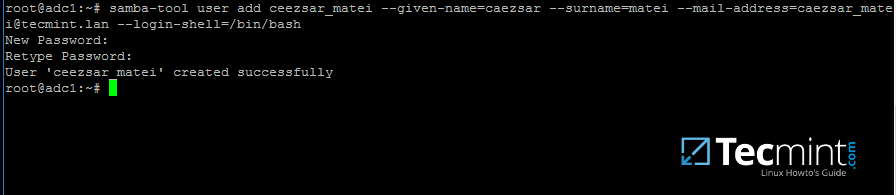
要在 AD 上创建用户,请使用以下命令:
samba-tool user add your_domain_user
要添加具有 AD 所需的几个重要字段的用户,请使用以下语法:
--------- review all options ---------
samba-tool user add -h
samba-tool user add your_domain_user --given-name=your_name --surname=your_username [email --login-shell=/bin/bash
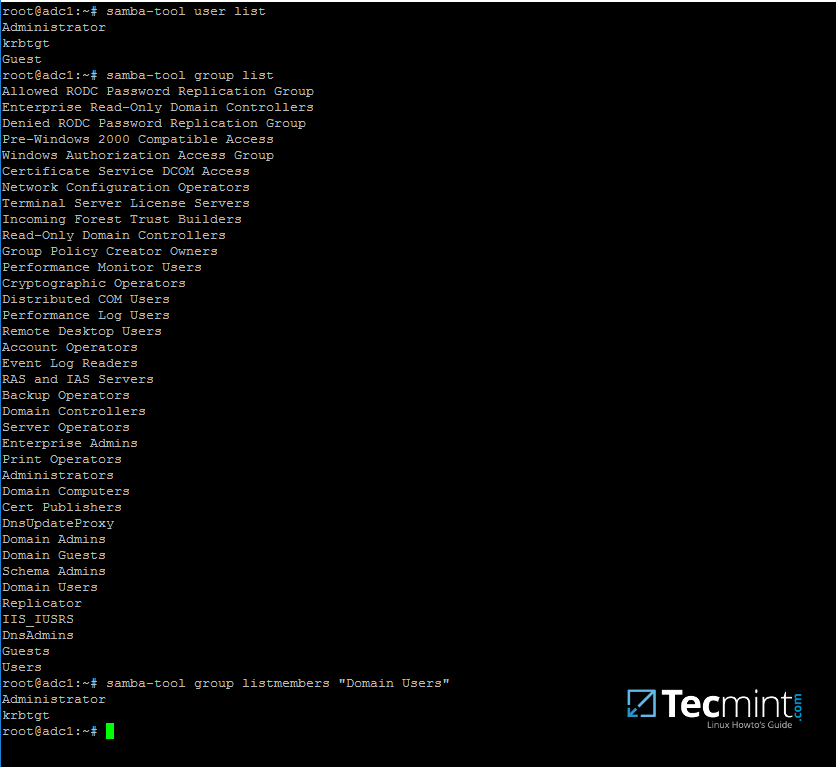
3.可以通过发出以下命令来获取所有 samba AD 域用户的列表:
samba-tool user list
4. 要删除 samba AD 域用户,请使用以下语法:
samba-tool user delete your_domain_user
5.通过执行以下命令重置 samba 域用户密码:
samba-tool user setpassword your_domain_user
6. 要禁用或启用 samba AD 用户帐户,请使用以下命令:
samba-tool user disable your_domain_user
samba-tool user enable your_domain_user
7. 同样,可以使用以下命令语法管理 samba 组:
--------- review all options ---------
samba-tool group add –h
samba-tool group add your_domain_group
8. 通过发出以下命令删除 samba 域组:
samba-tool group delete your_domain_group
9. 要显示所有 samba 域组,请运行以下命令:
samba-tool group list
10. 要列出特定组中的所有 samba 域成员,请使用以下命令:
samba-tool group listmembers "your_domain group"
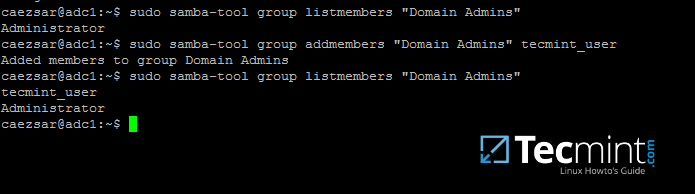
11. 可以通过发出以下命令之一来添加/删除 samba 域组中的成员:
samba-tool group addmembers your_domain_group your_domain_user
samba-tool group remove members your_domain_group your_domain_user
12. 如前所述,samba-tool 命令行界面还可用于管理您的 samba 域策略和安全性。
要查看您的 samba 域密码设置,请使用以下命令:
samba-tool domain passwordsettings show
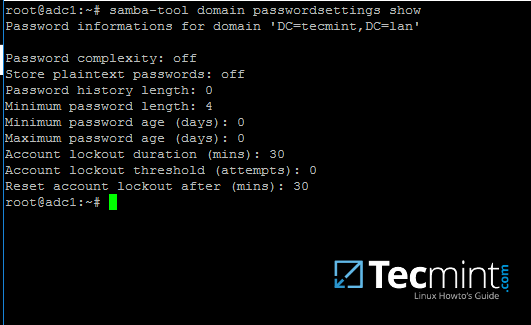
13.为了修改 samba 域密码策略,例如密码复杂程度、密码时效、长度、要记住多少旧密码以及域控制器所需的其他安全功能,请使用以下屏幕截图:指引。
---------- List all command options ----------
samba-tool domain passwordsettings -h
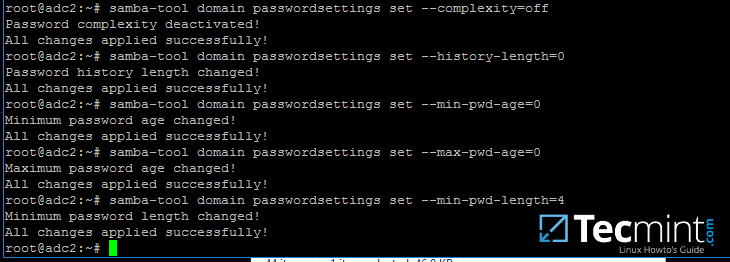
切勿在生产环境中使用如上所示的密码策略规则。上述设置仅用于演示目的。
步骤 2:使用 Active Directory 帐户进行 Samba 本地身份验证
14.默认情况下,AD用户无法在Samba AD DC环境之外的Linux系统上进行本地登录。
为了使用 Active Directory 帐户登录系统,您需要对 Linux 系统环境进行以下更改并修改 Samba4 AD DC。
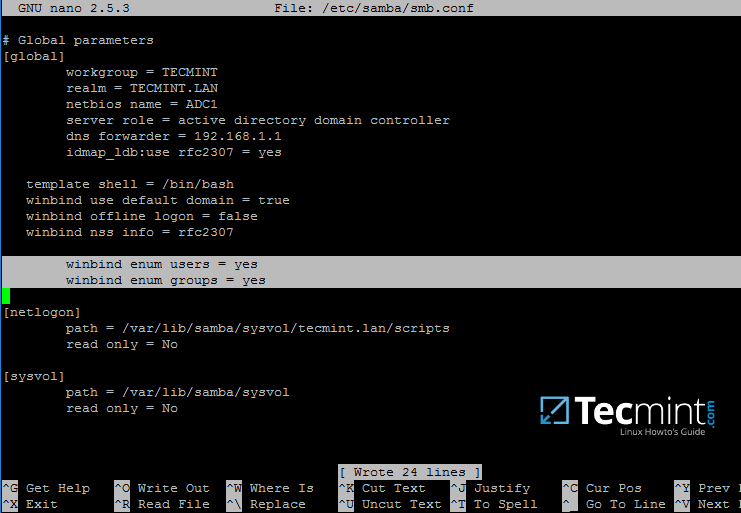
首先,打开 samba 主配置文件并添加以下行(如果缺少),如下面的屏幕截图所示。
sudo nano /etc/samba/smb.conf
确保配置文件中出现以下语句:
winbind enum users = yes
winbind enum groups = yes
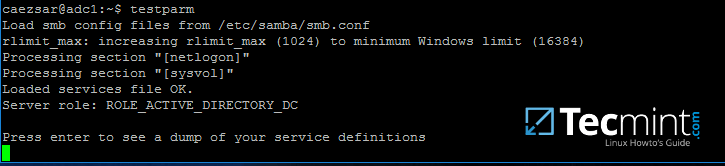
15. 完成更改后,使用 testparm 实用程序确保 samba 配置文件中没有发现错误,并通过发出以下命令重新启动 samba 守护进程。
testparm
sudo systemctl restart samba-ad-dc.service
16. 接下来,我们需要修改本地 PAM 配置文件,以便 Samba4 Active Directory 帐户能够在本地系统上进行身份验证并打开会话并创建主目录用户首次登录时的目录。
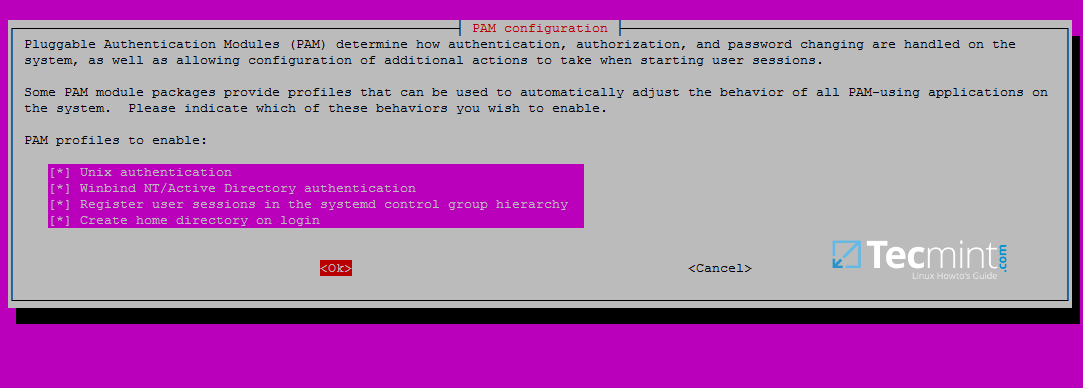
使用 pam-auth-update 命令打开 PAM 配置提示符,并确保使用 [space] 键启用所有 PAM 配置文件,如下面的屏幕截图所示。
完成后,按[Tab]键移至确定并应用更改。
sudo pam-auth-update
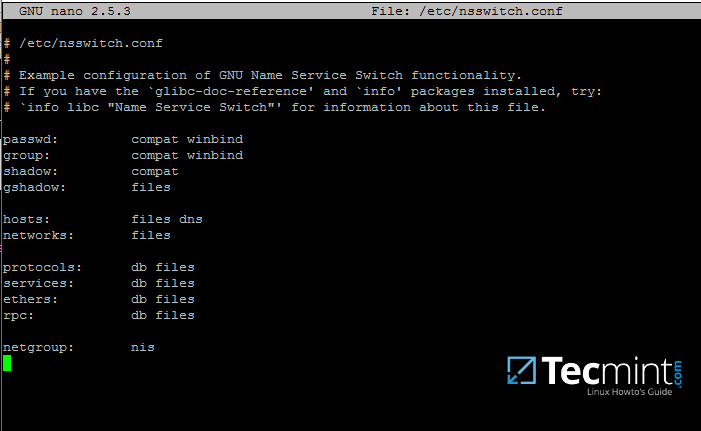
17. 现在,使用文本编辑器打开 /etc/nsswitch.conf 文件,并在密码和组行末尾添加 winbind 语句如下面的屏幕截图所示。
sudo vi /etc/nsswitch.conf
18.最后,编辑/etc/pam.d/common-password文件,搜索下面的行(如下面的屏幕截图所示)并删除use_authtok<声明。
此设置可确保 Active Directory 用户在 Linux 中进行身份验证时可以从命令行更改其密码。启用此设置后,在 Linux 上进行本地身份验证的 AD 用户无法从控制台更改其密码。
password [success=1 default=ignore] pam_winbind.so try_first_pass
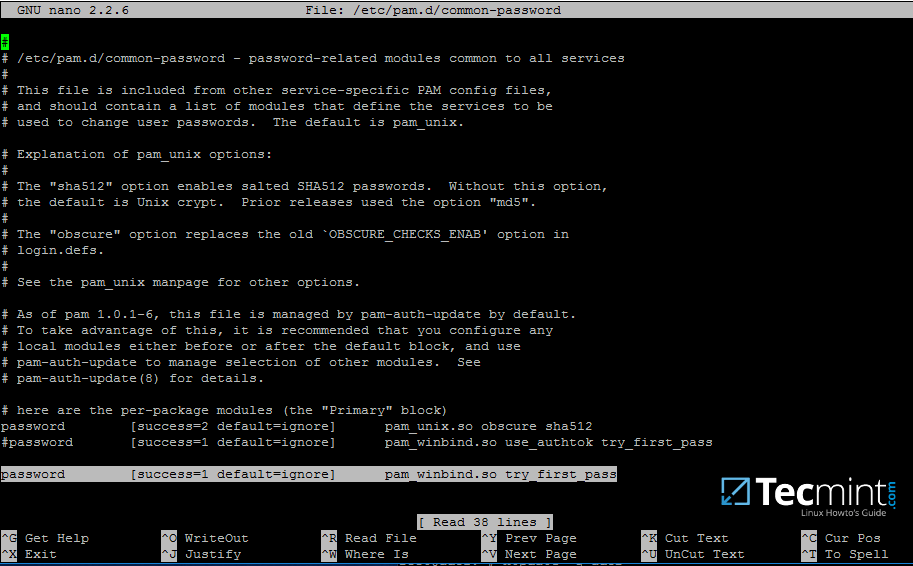
每次安装 PAM 更新并将其应用于 PAM 模块时或每次执行 pam-auth-update 命令时,请删除 use_authtok 选项。
19. Samba4 二进制文件带有一个内置的 winbindd 守护进程,并且默认启用。
因此,您不再需要单独启用和运行官方 Ubuntu 存储库中的 winbind 软件包提供的 winbind 守护进程。
如果系统上启动了旧的且已弃用的 winbind 服务,请确保禁用它并通过发出以下命令停止该服务:
sudo systemctl disable winbind.service
sudo systemctl stop winbind.service
虽然我们不再需要运行旧的 winbind 守护进程,但我们仍然需要从存储库安装 Winbind 软件包才能安装和使用 wbinfo 工具。
Wbinfo 实用程序可用于从 winbindd 守护程序的角度查询 Active Directory 用户和组。
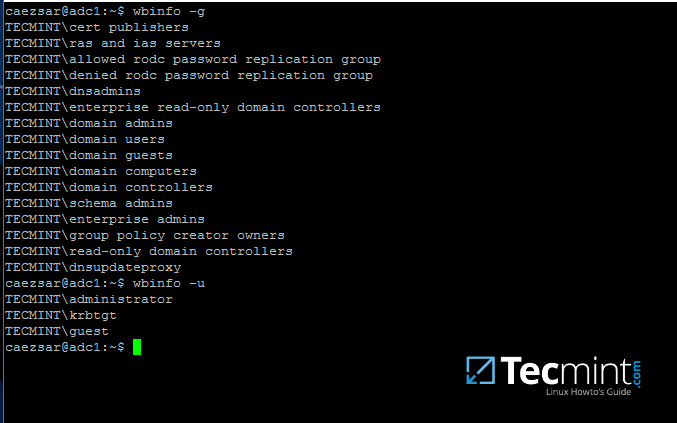
以下命令说明了如何使用 wbinfo 查询 AD 用户和组。
wbinfo -g
wbinfo -u
wbinfo -i your_domain_user

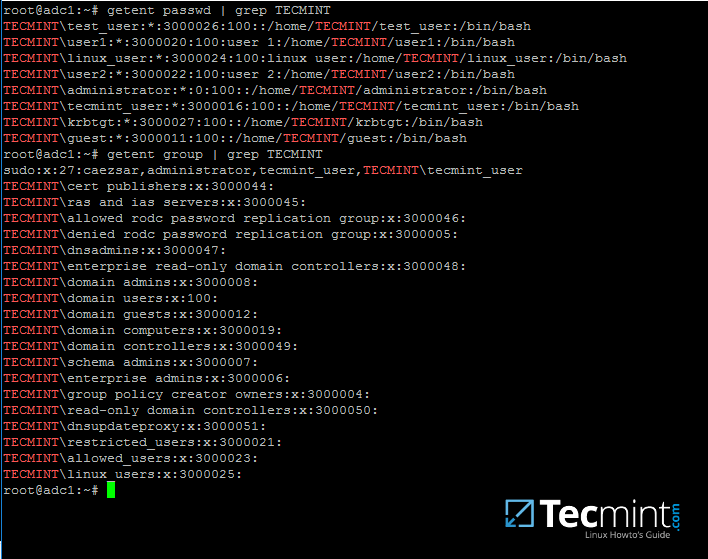
20. 除了wbinfo实用程序之外,您还可以使用getent命令行实用程序从名称服务切换库中查询Active Directory数据库,这些库在< /etc/nsswitch.conf 文件。
通过 grep 过滤器传送 getent 命令,以缩小仅与您的 AD 领域用户或组数据库相关的结果范围。
getent passwd | grep TECMINT
getent group | grep TECMINT
步骤 3:使用 Active Directory 用户登录 Linux
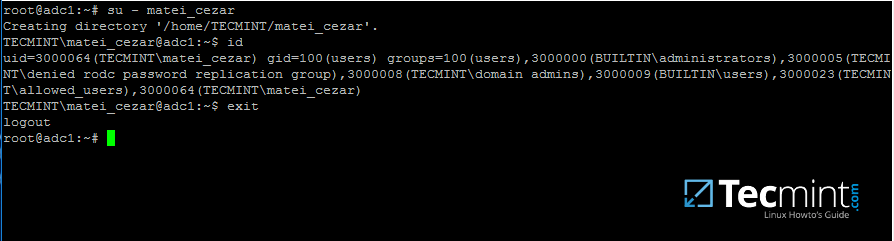
21.为了使用Samba4 AD用户在系统上进行身份验证,只需在su -AD用户名参数代码>命令。
首次登录时,控制台上将显示一条消息,通知您已在 /home/$DOMAIN/ 系统路径上创建了一个主目录,其名称为您的 AD 用户名。
使用id命令显示有关经过身份验证的用户的额外信息。
su - your_ad_user
id
exit
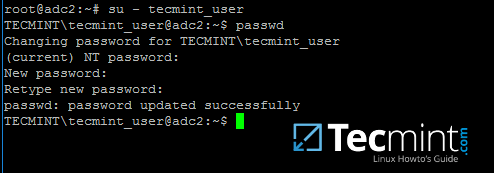
22. 要更改经过身份验证的 AD 用户的密码,请在成功登录系统后在控制台中键入 passwd 命令。
su - your_ad_user
passwd
23. 默认情况下,Active Directory 用户不会被授予 root 权限以在 Linux 上执行管理任务。
要向 AD 用户授予 root 权限,您必须通过发出以下命令将用户名添加到本地 sudo 组。
确保使用单引号 ASCII 将领域、斜杠和AD 用户名引起来。
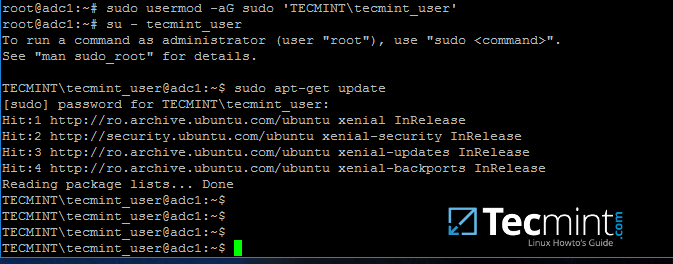
usermod -aG sudo 'DOMAIN\your_domain_user'
要测试 AD 用户是否在本地系统上具有 root 权限,请使用 sudo 权限登录并运行命令,例如 apt-get update。
su - tecmint_user
sudo apt-get update
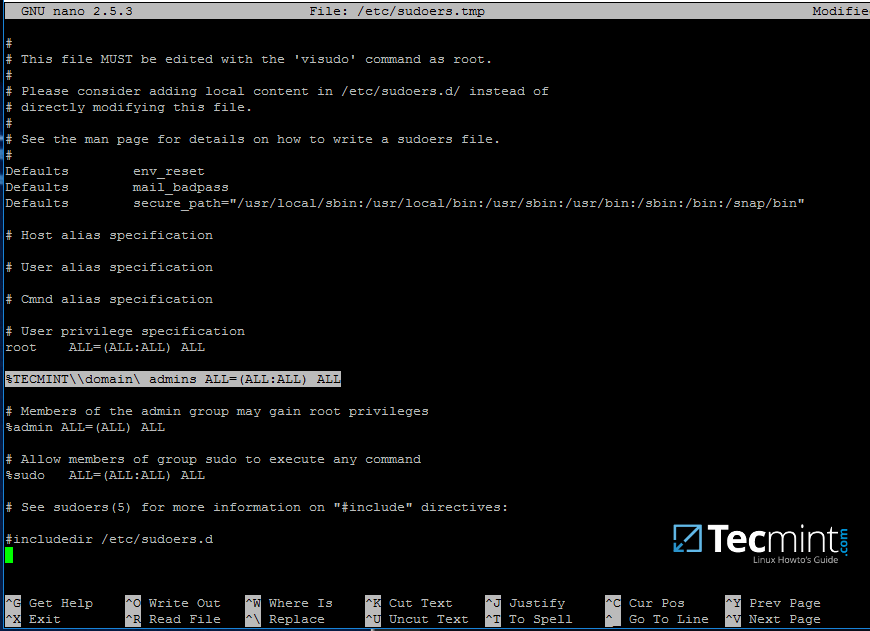
24. 如果您想为 Active Directory 组的所有帐户添加 root 权限,请使用 visudo 命令编辑 /etc/sudoers 文件,然后在 root 权限行之后添加以下行,如下面的屏幕截图所示:
%DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL
注意 sudoers 语法,这样就不会破坏事情。
Sudoers 文件不能很好地处理 ASCII 引号的使用,因此请确保使用 % 来表示您引用的是一个组,并使用反斜杠来表示如果您的组名包含空格(大多数 AD 内置组默认包含空格),请转义域名后面的第一个斜杠和另一个反斜杠以转义空格。另外,领域请用大写字母书写。
目前为止就这样了! 管理 Samba4 AD 基础设施还可以使用 Windows 环境中的多种工具来实现,例如 ADUC、DNS Manager、GPM > 或其他,可以通过从 Microsoft 下载页面安装RSAT包来获取。
要通过RSAT实用程序管理Samba4 AD DC,绝对有必要将Windows系统加入Samba4 Active Directory。这将是我们下一篇教程的主题,在此之前请继续关注 TecMint。